トップページ
![]() 研究活動
研究活動
![]() 研究チーム紹介
研究チーム紹介
![]() 高性能ビッグデータ研究チーム
高性能ビッグデータ研究チーム
高性能ビッグデータ研究チーム
English
チームプリンシパル 佐藤 賢斗
(さとう けんと) kento.sato[at]riken.jp (拠点:神戸)
kento.sato[at]riken.jp (拠点:神戸)- Emailの[at]は@にご変更ください。
- 2014
- 東京工業大学大学院 数理計算科学専攻 博士(理学)
- 2014
- 東京工業大学 学術国際情報センター ポスドク
- 2014
- 米国ローレンスリバモア国立研究所 ポスドク
- 2017
- 米国ローレンスリバモア国立研究所 研究員
- 2018
- 理化学研究所 計算科学研究センター(R-CCS) 高性能ビッグデータ研究チーム チームリーダー(現職)
- 2024
- 理化学研究所 計算科学研究センター(R-CCS) AI for Scienceプラットフォーム部門 AI学習・推論データ管理基盤開発ユニット ユニットリーダー(現職)
- 2025
- 理化学研究所 計算科学研究センター(R-CCS) 次世代計算基盤開発部門 先進的計算基盤技術開発ユニット ユニットリーダー(現職)
キーワード
- ビッグデータ処理基盤
- 機械学習/深層学習処理基板
- 耐障害性技術
- ファイルシステム
- 仮想化・コンテナ技術
研究概要
理化学研究所 計算科学研究センター 高性能ビッグデータ研究チームでは、スーパーコンピュータ「富岳」のような高性能計算機の高度化のためのシステム開発をしています。特に高性能計算(HPC)、ビッグデータ(Big Data)および人工知能(AI)の融合を目指しています。これを実現するために、高性能計算機の高度化に普遍的に必要とされる要素技術の研究開発を行うとともに、「ビッグデータや人工知能」計算の高度化のためのシステム開発(HPC for Big Data/AI)や「ビッグデータや人工知能」の技術を用いた高性能計算の高度化(Big Data/AI for HPC)の開発を行っており、また、将来の高性能計算機の設計するための技術開発も行っています。具体的には、並列I/Oの高速化・スケール化、階層型メモリ・ストレージ技術を活用した機械学習・深層学習の高速化・スケール化、不揮発性メモリの活用、スケーラブルかつ効率的な耐障害技術、高速ネットワーク上でのデータ圧縮・転送の効率化、プログラミング環境の高度化、次世代大規模システムのためにアーキテクチャ探索を行なっています。我々は国内外の企業、大学、国立研究所の研究者と積極的に連携し、高性能ビッグデータ処理基盤の確立を目指しています。
主な研究成果
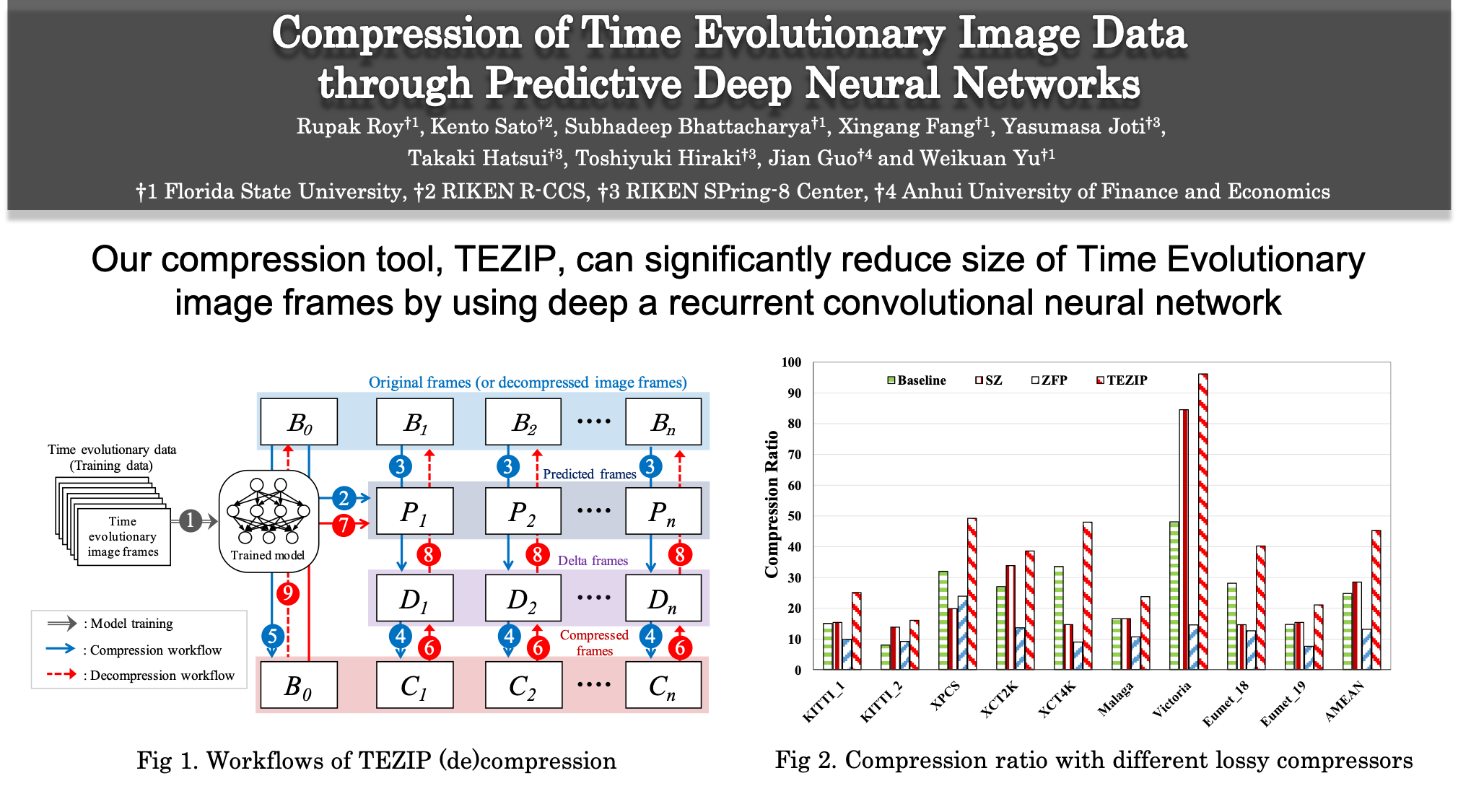
AI技術を活用したデータ圧縮
近年のディープニューラルネットワーク(DNN)の進歩により、時間発展型データの時間発展性を予測することが容易になっています。本研究では、AI技術を活用した圧縮フレームワーク(TEZIP)を開発しました。このTEZIPは、時間発展型データの連続したフレームに対し、高い圧縮率で高速なデータサイズ削減を可能とします。TEZIPは、まずPredNetと呼ばれるRecurrent Neural Networkで対象データの時間発展性を学習します。その後、圧縮の際にベースとなるフレームに基づいて将来の画像フレームを予測し、予測フレームと実際のフレームとの差分データに対し、量子化や符号化を行うことにより高い圧縮率を実現します。TEZIPの評価の結果、TEZIPは圧縮率の点で、x265などの既存の可逆圧縮手法に対し最大3.2倍、SZなどの不可逆圧縮手法に対し最大3.3倍の圧縮率を実現しました。
主要論文
-
Taiyu Wang, Qinglin Yang, Kaiming Zhu, Junbo Wang, Chunhua Su, Kento Sato,
“LDS-FL: Loss Differential Strategy based Federated Learning for Privacy Preserving,”
in IEEE Transactions on Information Forensics and Security, doi: 10.1109/TIFS.2023.3322328. , 2023 -
Takaaki Fukai, Kento Sato and Takahiro Hirofuchi,
“Analyzing I/O Performance of a Hierarchical HPC Storage System for Distributed Deep Learning”,
The 23rd International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT’22), December, 2022, Sendai, Japan -
Xi Zhu, Junbo Wang, Wuhui Chen, Kento Sato,
“Model compression and privacy preserving framework for federated learning”,
Future Generation Computer Systems, 2022, ISSN 0167-739X, https://doi.org/10.1016/j.future.2022.10.026 -
Amitangshu Pal, Junbo Wang, Yilang Wu, Krishna Kant, Zhi Liu, Kento Sato,
“Social Media Driven Big Data Analysis for Disaster Situation Awareness: A Tutorial”,
in IEEE Transactions on Big Data, doi: 10.1109/TBDATA.2022.3158431, Mar., 2022 -
Feiyuan Liang, Qinglin Yang, Ruiqi Liu, Junbo Wang, Kento Sato, Jian Guo,
“Semi-Synchronous Federated Learning Protocol with Dynamic Aggregation in Internet of Vehicles,”
in IEEE Transactions on Vehicular Technology, doi: 10.1109/TVT.2022.3148872, Feb., 2022 -
Akihiro Tabuchi, Koichi Shirahata, Masafumi Yamazaki, Akihiko Kasagi, Takumi Honda, Kouji Kurihara, Kentaro Kawakami, Tsuguchika Tabaru, Naoto Fukumoto, Akiyoshi Kuroda, Takaaki Fukai and Kento Sato,
“The 16,384-node Parallelism of 3D-CNN Training on An Arm CPU based Supercomputer”,
28th IEEE International Conference on High Performance Computing, Data, and Analytics (HiPC2021), Nov, 2021 -
Steven Farrell, Murali Emani, Jacob Balma, Lukas Drescher, Aleksandr Drozd, Andreas Fink, Geoffrey Fox, David Kanter, Thorsten Kurth, Peter Mattson, Dawei Mu, Amit Ruhela, Kento Sato,,Koichi Shirahata, Tsuguchika Tabaru, Aristeidis Tsaris, Jan Balewski, Ben Cumming, Takumi Danjo, Jens Domke, Takaaki Fukai, Naoto Fukumoto, Tatsuya Fukushi, Balazs Gerofi, Takumi Honda, Toshiyuki Imamura, Akihiko Kasagi, Kentaro Kawakami, Shuhei Kudo, Akiyoshi Kuroda, Maxime Martinasso, Satoshi Matsuoka, Kazuki Minami, Prabhat Ram, Takashi Sawada, Mallikarjun Shankar, Tom St. John, Akihiro Tabuchi, Venkatram Vishwanath, Mohamed Wahib, Masafumi Yamazaki, Junqi Yin and Henrique Mendonca,
“MLPerf HPC: A Holistic Benchmark Suite for Scientific Machine Learning on HPC Systems”,
The Workshop on Machine Learning in High Performance Computing Environments (MLHPC) 2021 in conjunction with SC21, Nov, 2021 -
Rupak Roy, Kento Sato, Subhadeep Bhattacharya, Xingang Fang, Yasumasa Joti, Takaki Hatsui, Toshiyuki Hiraki, Jian Guo and Weikuan Yu:
“Compression of Time Evolutionary Image Data through Predictive Deep Neural Networks”
In proceedings of the 21 IEEE/ACM International Symposium on Cluster, Cloud and Internet Computing (CCGrid 2021), (2021). -
Tonmoy Dey, Kento Sato, Bogdan Nicolae, Jian Guo, Jens Domke, Weikuan Yu, Franck Cappello, and Kathryn Mohror:
“Optimizing Asynchronous Multi-Level Checkpoint/Restart Configurations with Machine Learning”
The IEEE International Workshop on High-Performance Storage, (2020). -
Chapp, D., Rorabaugh, D., Sato, K., Ahn, D. H., & Taufer, M:
“A three-phase workflow for general and expressive representations of nondeterminism in HPC applications”
The International Journal of High Performance Computing Applications, 33(6), 1175–1184. (2019).