トップページ
![]() 研究活動
研究活動
![]() 計算の科学・計算による科学研究チーム紹介
計算の科学・計算による科学研究チーム紹介
![]() 過去の研究チーム紹介
過去の研究チーム紹介
![]() プログラミング環境研究チーム(佐藤 三久)
プログラミング環境研究チーム(佐藤 三久)
プログラミング環境研究チーム(佐藤 三久)
English
チームリーダー 佐藤 三久
(さとう みつひさ) (拠点:神戸)
(拠点:神戸)- Emailの[at]は@にご変更ください。
- 1982
- 東京大学理学部情報科学科卒業
- 1986
- 同大学院理学系研究科博士課程中退。理学博士
- 1986
- 新技術事業団後藤磁束量子情報プロジェクトに参加
- 1991
- 通産省電子技術総合研究所入所
- 1996
- 新情報処理開発機構並列分散システムパフォーマンス研究室 室長
- 2001
- 筑波大学 システム情報系教授
- 2007
- 同大学計算科学研究センターセンター長
- 2010
- AICSプログラミング環境研究チーム チームリーダー(現職)
- 2014
- フラッグシップ2020プロジェクト副プロジェクトリーダー、アーキテクチャ開発チームチームリーダー
- 2016
- 筑波大学 連携大学院教授、名誉教授
- 2023
- 順天堂大学教授(現職)
- 2023
- R-CCS量子 HPC 連携プラットフォーム部門 部門長、量子HPCソフトウェア環境開発ユニット ユニットリーダー(現職)
キーワード
- 並列プログラミング言語
- 並列処理
- 高性能計算
研究概要
当研究チームでは、大規模な並列システムの能力を引き出し、かつ、難しいといわれる並列プログラミングの生産性を向上させるためのプログラミング言語およびプログラミングモデルの研究開発を行ってきました。その一つが、PGAS(Partitioned Global Address Space)モデルをベースとした新しいプログラミング言語「XcalableMP」の開発です。我々は、Omni XMPコンパイラというレファレンス実装を行い、「京」に向けた最適化やPGASモデルの性能評価、さらに「京」以外のGPUなどの演算加速機構をもつ並列システムへの適用を行ってきました。現在、「富岳」においても、利用できるように開発を進めており、ノード内の多数のコアが効率的に利用できるように拡張機能について研究開発を進めています。
これからのエクサスケール計算のための高性能高生産性プログラミング環境に向けて、XcalableMPの次のバージョンであるXcalableMP 2.0の研究開発を進めています。大規模なメニーコアプロセッサ並列システムを活用するためのプログラミングが重要な課題となるため、マルチタスク機能とPGASの片方向通信を統合したモデルを提案しています。これにより、時間のかかる大域的な同期を排除し、RDMAによる軽量の通信機構と計算のオーバーラップが可能となり、効率的な実行が可能です。これについては、「富岳」での演算効率の向上に寄与できると期待しています。また、これからの演算加速機構として、書き換え可能ハードウエアデバイスであるFPGA向けのプログラミングの研究も進めています。
主な研究成果
演算加速機構を持つ並列システムのためのプログラミング言語XcalableACCを開発
XGPUなどの演算加速機構を各ノードに持つ並列システムが多く使われるようになってきていますが、プログラミングの複雑さが問題になっています。XcalableACCは、これまで開発してきた並列プログラミング言語XcalableMPにGPUのためのプログラミング仕様であるOpenACCを統合したプログラミング言語です。XcalableMPの機能を用いてノード間のデータ分散や計算の割り当てを記述し、OpenACCを用いてGPUへの処理のオフロードを記述します。OpenACCによるオフロードはXcalableMPによる分散されたデータに対応するだけでなく、GPU間の直接通信を記述できるように拡張されています。以下に示すように、ラプラス方程式の逐次プログラムに対して、XcalableMPの記述(赤)、OpenACCの記述(青)を加えることでGPUクラスタに対応ができます。

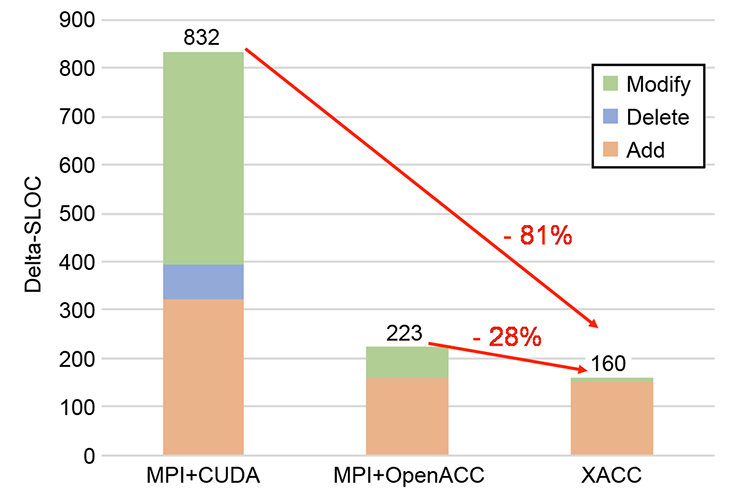
QCDのアプリケーションを用いたケーススタディでは、842行のCコードについて、XcalableACCでは160行あまりの追加で並列化ができるのに対し、従来のMPIとCUDAを使った場合には832行の追加修正が必要となり、高い生産性を提供できることを示しています。
また、性能については、MPIとCUDAを使ったケースに比べて、95%から99%の性能となり、ほぼと同等の性能が得られることがわかっています。
主要論文
- Masahiro Nakao, Hitoshi Murai, Hidetoshi Iwashita, Taisuke Boku, Mitsuhisa Sato.:
"Implementation and evaluation of the HPC Challenge benchmark in the XcalableMP PGAS language,"
International Journal of High Performance Computing Applications, Mar. 2017. - Jinpil Lee, Keisuke Tsugane, Hitoshi Murai, Mitsuhisa Sato.:
"OpenMP Extension for Explicit Task Allocation on NUMA Architecture,"
12th International Workshop on OpenMP, Nara, Japan, Oct. 2016. - Hitoshi Murai, Taisuke Boku, Matthias S. Müller, Christian Terboven, Joachim Protze, Pablo Reble, Serge G. Petiton, Nahid Emad.:
"MYX: MUST Correctness Checking for YML & XMP Programs,"
ISC16/HPCAsia Poster, Frankfurt, Germany, Jun. 2016. - Miwako Tsuji, Jinpil Lee, Taisuke Boku, Mitsuhisa Sato.:
"SCAMP: A "Pseudo"-Trace Driven Simulation toward Scalable Network Evaluation,"
ISC16/HPCAsia Poster, Frankfurt, Germany, Jun. 2016. - Jinpil Lee, Tsugane Keisuke, Daisuke Sugiyama, Murai Hitoshi, Mitsuhisa Sato.:
"XMP-Tasklet: Multitasking in a PGAS Language for Many-Core Clusters,"
ISC16/HPCAsia Poster, Frankfurt, Germany, Jun. 2016. - Mitsuhisa Sato, Hitoshi Murai, Masahiro Nakao, Hidetoshi Iwashita, Jinpil Lee, Akihiro Tabuchi.:
"Omni Compiler and XcodeML: An Infrastructure for Source-to-Source Transformation,"
Platform for Advanced Scientific Computing Conference (PASC16), Lausanne, Switzerland, Jun. 2016. - Miwako Tsuji, Mitsuhisa Sato.:
"Fault Tolerance Features of a New Multi-SPMD Programming/Execution Environment,"
Proceedings of First International Workshop on Extreme Scale Programming Models and Middleware, Texas, USA, Nov., 2015. - Hidetoshi Iwashita, Masahiro Nakao, Mitsuhisa Sato.:
"Preliminary Implementation of Coarray Fortran Translator Based on Omni XcalableMP,"
The 9th International Conference on Partitioned Global Address Space Programming Models (PGAS2015), Washington, D.C. USA, Sep., 2015. - Hitoshi Sakagami, Hitoshi Murai.:
"Performance of Three-dimensional Fluid Simulation with XcalableMP on the K computer,"
ISC 2015, Frankfurt, Germany, Jul. 2015. - Masahiro Nakao, Hitoshi Murai, Takenori Shimosaka, Akihiro Tabuchi, Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato.:
"XcalableACC: Extension of XcalableMP PGAS Language using OpenACC for Accelerator Clusters,"
Workshop on accelerator programming using directives (WACCPD), New Orleans, LA, USA, Nov., 2014.