TOP
![]() Research
Research
![]() Research Teams
Research Teams
![]() Past Research Teams
Past Research Teams
![]() System Software Research Team (Ishikawa)
System Software Research Team (Ishikawa)
System Software Research Team (Ishikawa)
Japanese
Team Leader Yutaka Ishikawa
- 2014
- Team Leader, System Software Research Team and System Software Development Team, Leader of Flagship 2020 Project, AICS, RIKEN
- 2006
- Professor, The University of Tokyo
- 2002
- Associate Professor, The University of Tokyo
- 1993
- Chief, Massively Parallel Software Laboratory, Real World Computing Partnership (RWCP).
- 1987
- ElectroTechnical Laboratory (currently reorganized as AIST)
- 1987
- Doctor, Electrical Engineering from Keio University
Research summary
Development of Novel System Software for HPC, Big Data and AI
Our research team is responsible for developing an advanced system software stack. We are also conducting research and development for the supercomputer Fugaku and for future systems, taking into consideration continuity of the user environment and usability. The software stack under development is made up of the following:
- OS kernel
We are developing a lightweight multi-kernel, called McKernel, for many-core type parallel computers. Applications running on Linux run on Mckernel without recompilation. McKernel currently runs on Intel 's latest Xeon and Xeon Phi processors, and is being implemented for Fugaku. - A New Process/Thread Execution Model
We are developing a new process/thread execution model, called PiP, in which processes share the same address space. PiP is implemented at user-level without any OS kernel modifications, and thus it is highly portable. - MPI communication library
We are implementing the MPICH communication library, an implementation of the MPI communication library developed mainly by Argonne National Laboratories, for the supercomputer Fugaku. In particular, we are developing a mechanism that efficiently utilizes the Fugaku communication hardware. - File I / O library
We are developing a DTF file I/O library, realizing a real-time job-to-job file I/O library.
Main research results
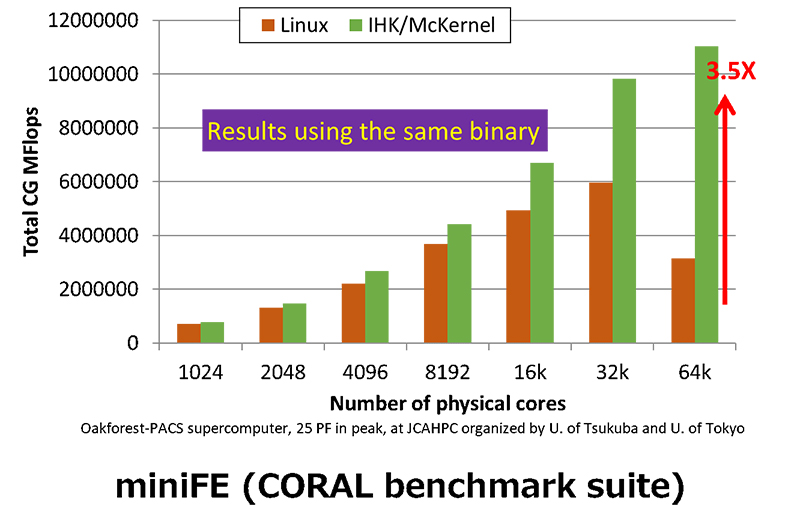
Development of McKernel: a Linux-compatible lightweight kerne
McKernel has been evaluated using the miniFE benchmark code, a Finite Element mini-測application which implements a couple of kernels representative of implicit finite-element applications. The following Figure shows a result running on Oakforest-PACS, which is operated by the Joint Center for Advanced High Performance Computing that is run by the University of Tsukuba and the University of Tokyo, which is operated by the Joint Center for Advanced High Performance Computing that is run by the University of Tsukuba and the University of Tokyo. McKernel achieves more than 3.5x faster than Linux.
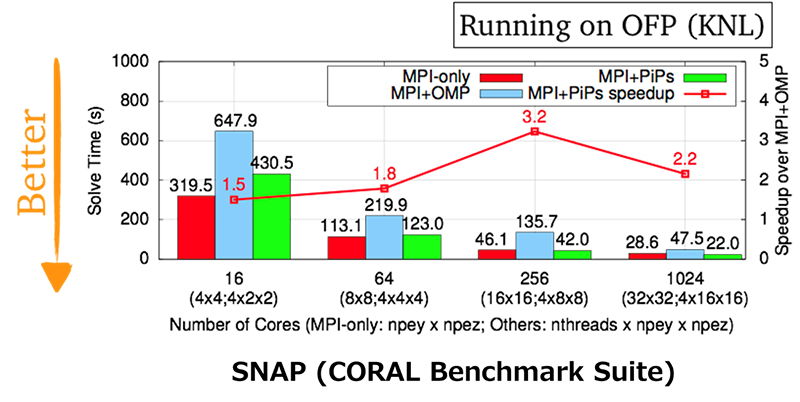
Development of PiP: a new process/thread execution model
We have evaluated PiP using the SNAP benchmark code which is a proxy application to model the performance of a modern discrete ordinates transport application. It uses newer MPI and OpenMP features, such as thread multiple communication and nested threads. We implemented the MPI with PiP version that replaces OpenMP threads with PiP tasks. The following Figure shows a result running on Oakforest-PACS. It achieves 2.5x faster than MPI+OpenMP in 1024 cores.