TOP
![]() Research
Research
![]() Research Teams
Research Teams
![]() Past Research Teams
Past Research Teams
![]() Programming Environment Research Team (Mitsuhisa Sato)
Programming Environment Research Team (Mitsuhisa Sato)
Programming Environment Research Team (Mitsuhisa Sato)
Japanese
Team Leader Mitsuhisa Sato
 (Lab location: Kobe)
(Lab location: Kobe)- Please change [at] to @
- 2023
- Director/Unit Leader, Quantum-HPC Hybrid Software Environment Unit, Quantum-HPC Hybrid Platform Division, R-CCS (-present)
- 2023
- Professor , Juntendo University (-present)
- 2016
- Professor(Cooperative Graduate School Program)and Professor Emeritus, University of Tsukuba (-present)
- 2014
- Team Leader, Architecture Development Team of Flagship 2020 Project, AICS (renamed R-CCS in 2018), RIKEN
- 2010
- Team Leader, Programming Environment Research Team, AICS (renamed R-CCS in 2018), RIKEN (-present)
- 2007
- Director , Center for Computational Sciences, University of Tsukuba
- 2001
- Professor , Graduate School of Systems and Information Engineering, University of Tsukuba (-present)
- 1996
- Chief, Parallel and Distributed System Performance Laboratory in Real World Computing Partnership, Japan.
- 1991
- Senior Researcher, ElectroTechnical Laboratory (-1996)
- 1984
- M.S. and Ph.D. in Information Science, The University of Tokyo (-1990)
Keyword
- Parallel Programming Language
- Parallel Processing
- High Performance Computing
Research summary
We are researching and developing parallel programming models and a new programming language to exploit the full potential of large-scale parallel systems, as well as working to increase productivity of parallel programming. The programming language, called XcalableMP (XMP), is based on the PGAS (Partitioned Global Address Space) model, which was originally designed by the Japanese HPC language research community. We are working on a reference XMP compiler, the Omni XMP compiler, and have deployed it on several systems including the K computer for users, and conducted a performance study and optimization of the PGAS language. We also have developed an extension for an accelerator cluster beyond the K computer. Currently, we are working on the development of XcalableMP for "Fugaku" supercomputer with researches on some functional extensions to make use of many-core in "Fugaku" processor efficiently.
Towards the high-performance, and highly productive programming model for exascale computing, we are working on a new version of XcalableMP: XcalableMP 2.0. As it will be an important issue how to exploit the performance of a large-scale many-core system such as "Fugaku", we are proposing the programming model to integrate task-parallelism and RDMA operation by PGAS model. It can improve the performance by removing time-consuming global synchronization and enabling the overlap of computation and communication. It is expected to improve the performance of several program using many-core processor of "Fugaku" supercomputer. And, our team is also carrying out the research on the programming model for FPGA (field-programmable gate array) as a future accelerator device.
Main research results
Development of high-performance and highly-productive XcalableACC parallel language for parallel systems with accelerators
Although parallel systems with accelerators such as GPUs have come to be widely used, it is pointed out that programming for such system is often not easy and time-consuming. We have developed a new programming language called XcalableACC, which integrates OpenACC for offloading operations to GPUs with XcalableMP developed by our team. XcalableMP is used to describe the data distribution and the work assignment for each node, and OpenACC is used to describe offloading to GPUs. The XcalableACC extension enables not only a global distributed data to be offloaded to GPU, but also communication between GPUs. As shown in the program below, the solver of laplace equation can be parallelized by just adding XcalableMP directives (red) and OpenACC directives (blue) to the sequential code.

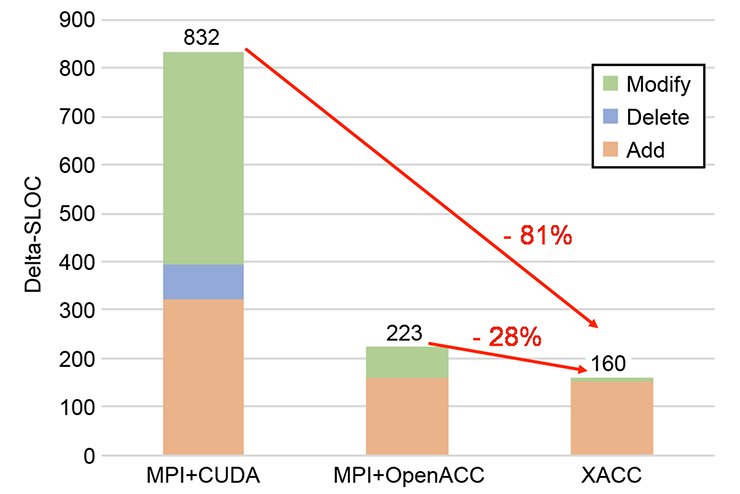
Our case-study using QCD application indicates the high productivity because the sequential version of the program can be parallelized by adding just 160 lines of XcalableACC code to 824 lines of the original code written in C while 832 lines of addition and modification are required when using the MPI and CUDA.
The XcalableACC code archived the comparable performance, from 95% to 99%, to the version of MPI and CUDA.
Representative papers
- Masahiro Nakao, Hitoshi Murai, Hidetoshi Iwashita, Taisuke Boku, Mitsuhisa Sato.:
"Implementation and evaluation of the HPC Challenge benchmark in the XcalableMP PGAS language,"
International Journal of High Performance Computing Applications, Mar. 2017. - Jinpil Lee, Keisuke Tsugane, Hitoshi Murai, Mitsuhisa Sato.:
"OpenMP Extension for Explicit Task Allocation on NUMA Architecture,"
12th International Workshop on OpenMP, Nara, Japan, Oct. 2016. - Hitoshi Murai, Taisuke Boku, Matthias S. Müller, Christian Terboven, Joachim Protze, Pablo Reble, Serge G. Petiton, Nahid Emad.:
"MYX: MUST Correctness Checking for YML & XMP Programs,"
ISC16/HPCAsia Poster, Frankfurt, Germany, Jun. 2016. - Miwako Tsuji, Jinpil Lee, Taisuke Boku, Mitsuhisa Sato.:
"SCAMP: A "Pseudo"-Trace Driven Simulation toward Scalable Network Evaluation,"
ISC16/HPCAsia Poster, Frankfurt, Germany, Jun. 2016. - Jinpil Lee, Tsugane Keisuke, Daisuke Sugiyama, Murai Hitoshi, Mitsuhisa Sato.:
"XMP-Tasklet: Multitasking in a PGAS Language for Many-Core Clusters,"
ISC16/HPCAsia Poster, Frankfurt, Germany, Jun. 2016. - Mitsuhisa Sato, Hitoshi Murai, Masahiro Nakao, Hidetoshi Iwashita, Jinpil Lee, Akihiro Tabuchi.:
"Omni Compiler and XcodeML: An Infrastructure for Source-to-Source Transformation,"
Platform for Advanced Scientific Computing Conference (PASC16), Lausanne, Switzerland, Jun. 2016. - Miwako Tsuji, Mitsuhisa Sato.:
"Fault Tolerance Features of a New Multi-SPMD Programming/Execution Environment,"
Proceedings of First International Workshop on Extreme Scale Programming Models and Middleware, Texas, USA, Nov., 2015. - Hidetoshi Iwashita, Masahiro Nakao, Mitsuhisa Sato.:
"Preliminary Implementation of Coarray Fortran Translator Based on Omni XcalableMP,"
The 9th International Conference on Partitioned Global Address Space Programming Models (PGAS2015), Washington, D.C. USA, Sep., 2015. - Hitoshi Sakagami, Hitoshi Murai.:
"Performance of Three-dimensional Fluid Simulation with XcalableMP on the K computer,"
ISC 2015, Frankfurt, Germany, Jul. 2015. - Masahiro Nakao, Hitoshi Murai, Takenori Shimosaka, Akihiro Tabuchi, Toshihiro Hanawa, Yuetsu Kodama, Taisuke Boku, Mitsuhisa Sato.:
"XcalableACC: Extension of XcalableMP PGAS Language using OpenACC for Accelerator Clusters,"
Workshop on accelerator programming using directives (WACCPD), New Orleans, LA, USA, Nov., 2014.