TOP
![]() Research
Research
![]() Research Teams
Research Teams
![]() Processor Research Team
Processor Research Team
Processor Research Team
Japanese
Team Principal Kentaro Sano
 kentaro.sano[at]riken.jp (Lab location: Kobe)
kentaro.sano[at]riken.jp (Lab location: Kobe)- Please change [at] to @
- 2025
- Unit Leader, Next-Generation HPC Infrastructure System Development Unit, Next-Generation HPC Infrastructure Development Division, RIKEN R-CCS (-present)
- 2024
- Unit Leader, Advanced AI Device Development Unit, AI for Science Platform Division, RIKEN R-CCS (-present)
- 2019
- Visiting Professor, Graduate School of Information Sciences, Tohoku University
- 2017
- Team Leader, Processor Research Team, AICS (renamed R-CCS in 2018), RIKEN (-present)
- 2006
- Visiting Researcher, Imperial College, London
- 2005
- Associate Professor, Graduate School of Information Sciences, Tohoku University
- 2001
- Assistant Professor, Graduate School of Information Sciences, Tohoku University
- 2000
- Assistant Professor, Graduate School of Engineering, Tohoku University
- 2000
- Graduated from Computer and Mathematical Sciences, Graduate School of Information Sciences, Tohoku University
Keyword
- Computer Architecture
- Domain-specific hardware design
- Hardware Algorithms
- Advanced AI Device
- Fault-tolerant quantum computer
Research summary
We conduct research on high-performance and low-power computer architectures, considering technological trends in semiconductor manufacturing and packaging technologies and memory technologies as follows:
- Next-generation computer architecture for HPC and AI, in particular, coarse-grained reconfigurable arrays (CGRAs).
- Application-specific computer architecture optimized for each problem. For example, quantum error correction hardware, and hardware for near-sensor processing in synchrotron radiation facilities
- Systems for research on high-performance application-specific computer architectures. Especially, an FPGA cluster system
Main research results
Coarse-grained Reconfigurable Array (CGRA) for HPC and AI
We research CGRA, an architecture based on the dataflow computation model. Through collaboration with the University of Toronto, we have developed the basic architecture, RIKEN CGRA, and conducted design space exploration with it.
Quantum error correction hardware for fault-tolerant quantum computers (FQTC)
To solve the problem of errors of qubits and measurement, FTQC is required. We develop hardware to correct errors with a surface code at low latency and high throughput required, have made prototype design and its evaluation.
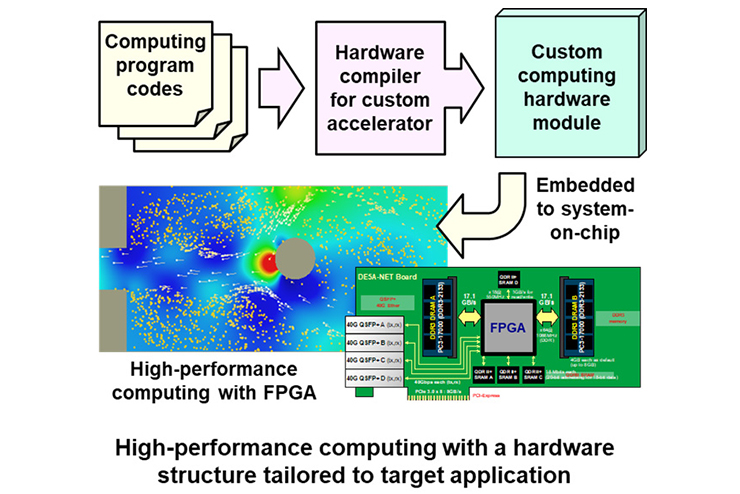
FPGA cluster, ESSPER, as a platform for research on application-specific high-perfornance computer architecture
As semiconductor scaling becomes more and more difficult to improve power efficiency, application-specific computer architectures are attracting attention. We have developed ESSPER (Elastic and Scalable System for High-Performance Reconfigurable Computing) that is an FPGA cluster. Also we have developed Virtual circuit-switching network (VCSN) that can build virtual topogies on top of a packet-switching network in FPGA cluster.
Algorithms and hardware designs for data compression
To solve the problem of data transfer that can be a bottleneck and power consuming in a system, we developed data compression hardware for high-throughput lossless compression of numerical data streams.
Representative papers
- Franck Cappello, Sheng Di, Robert Underwood, Dingwen Tao, Jon Calhoun, Yoshii Kazutomo, Kento Sato, Amarjit Singh, Luc Giraud, Emmanuel Agullo, Xavier Yepes, Mario Acosta, Sian Jin, Jiannan Tian, Frédéric Vivien, Boyuan Zhang, Kentaro Sano, Tomohiro Ueno, Thomas Grützmacher, Hartwig Anzt
"Multifacets of lossy compression for scientific data in the Joint-Laboratory of Extreme Scale Computing"
FGCS (Elsevier Future Generation Computer Systems), Vol.163, DOI:10.1016/j.future.2024.05.022, 2024. - Juan Miguel de Haro Ruiz, Carlos Alvarez Martınez, Daniel Jimenez-Gonzalez, Xavier Martorell, Tomohiro Ueno, Kentaro Sano, Burkhard Ringlein, Francois Abel, Beat Weiss
"Automated parallel execution of distributed task graphs with FPGA clusters"
FGCS (Elsevier Future Generation Computer Systems), Vol.160, Issue C, pp.808-824, DOI:10.1016/j.future.2024.06.041, 2024. - Tomohiro Ueno, Emanuele Del Sozzo, Kentaro Sano
"Flexible Systolic Array Platform on Virtual 2-D Multi-FPGA Plane"
Proceedings of HPC Asia 2024: The International Conference on High Performance Computing in Asia-Pacific Region, pp.84–94, DOI: 10.1145/3635035.3637285, Jan 25–27, 2024. - Emanuele Del Sozzo, Xinyuan Wang, Boma Adhi, Carlos Cortes, Jason Anderson, Kentaro Sano
"Exploration of Trade-offs Between General-Purpose and Specialized Processing Elements in HPC-Oriented CGRA"
Proceedings of IEEE International Parallel & Distributed Processing Symposium (IPDPS), pp.668-680, DOI: 10.1109/IPDPS57955.2024.00065., 2024. - Emanuele Del Sozzo, Davide Conficconi, Kentaro Sano
"Across Time and Space: Senju’s Approach for Scaling Iterative Stencil Loop Accelerators on Single and Multiple FPGAs"
FPT Journal Track with ACM Transactions on Reconfigurable Technology and Systems (TRETS), Vol.17, Issue.2, Article No.28, pp.1-33, DOI: 10.1145/3634920, 2024. - Philippos Papaphilippou, Kentaro Sano, Boma A. Adhi, and Wayne Luk
"Experimental survey of FPGA-based monolithic switches and a novel queue balancer"
IEEE Transactions on Parallel and Distributed Systems (TPDS), Vol.34, no.5, pp.1621-1634, DOI: 10.1109/TPDS.2023.3244589, 2023. - Kentaro Sano, Atsushi Koshiba, Takaaki Miyajima, and Tomohiro Ueno
"ESSPER: Elastic and Scalable FPGA-Cluster System for High-Performance Reconfigurable Computing with Supercomputer Fugaku"
Proceedings of HPC Asia2023, pp.140-150, DOI: 10.1145/3578178.3579341, 2023. - Tomohiro Ueno and Kentaro Sano
"VCSN: Virtual Circuit-Switching Network for Flexible and Simple-to-Operate Communication in HPC FPGA Cluster"
ACM Transactions on Reconfigurable Technology and Systems (TRETS), Vol.16, Issue.2, Article No.25, pp.1-32, DOI: 10.1145/3579848, 2023. - Boma Adhi, Carlos Cortes, Yiyu Tan, Takuya Kojima, Artur Podobas, and Kentaro Sano
"The Cost of Flexibility: Embedded versus Discrete Routers in CGRAs for HPC"
Proceedings of IEEE Cluster Conference (CLUSTER), pp.347-356, DOI: 10.1109/CLUSTER51413.2022.00046, Sep 6-9, 2022. - Artur Podobas, Kentaro Sano, and Satoshi Matsuoka
"A Survey on Coarse-Grained Reconfigurable Architectures from a Performance Perspective"
IEEE Access, Vol.8, pp.146719-146743, DOI:10.1109/ACCESS.2020.3012084, 2020.