Hybrid MPI/OpenMP calculation with spdyn
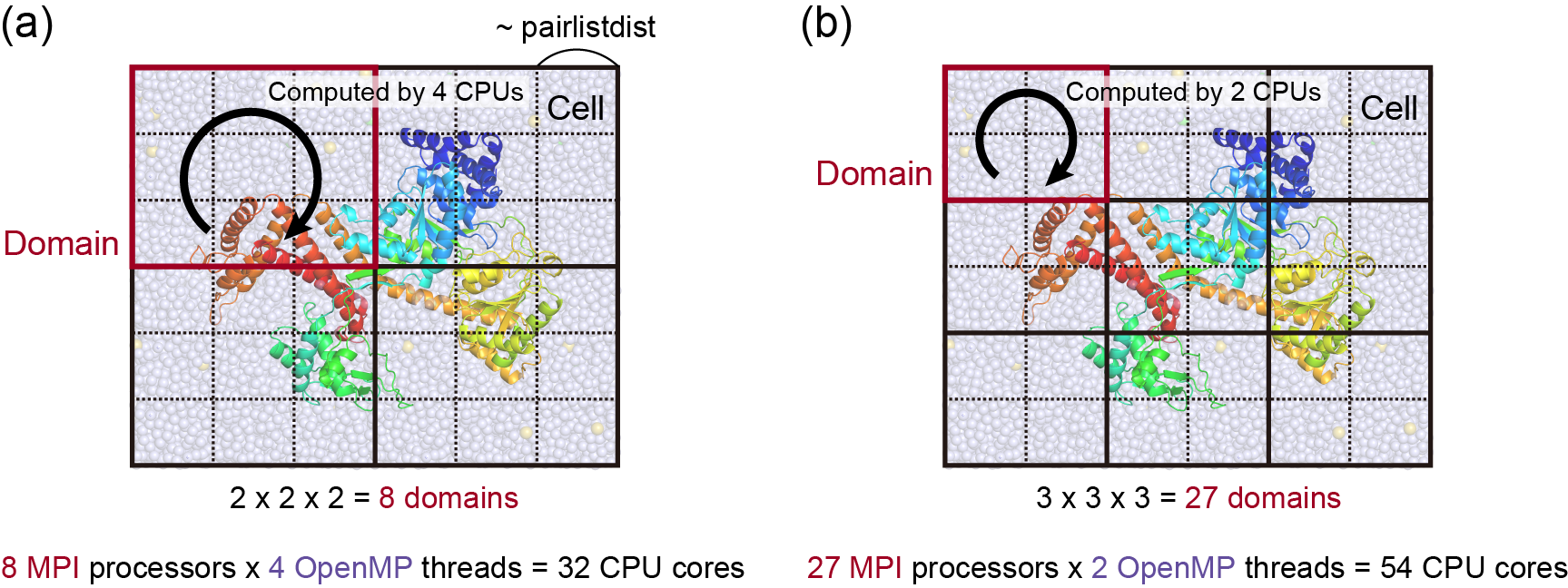
In order to get the best performance of spdyn, the user is recommended to understand a basic scheme of parallel calculation in spdyn. Spdyn uses a domain decomposition method, where the simulation box is divided into some domains according to the number of MPI processors. The domain is further divided into some cells, each of whose size is adjusted to be approximately equal to or larger than pairlistdist specified in the control file. Here, all domains or cells have the same shape and size. Each MPI processor is assigned to each domain, and data transfer or communication about atomic coordinates and forces is achieved between only neighboring domains. In addition, calculation of bonded and non-bonded interactions in each domain is parallelized based on the OpenMP protocol. These schemes realize hybrid MPI/OpenMP calculation, which is more efficient than flat MPI calculation on recent computers with multiple CPU cores. Because MPI and OpenMP are designed for distributed-memory and shared-memory architectures, respectively, MPI is mainly used for parallelization between nodes and OpenMP is used within one node. The following figures illustrate examples of hybrid MPI/OpenMP calculation, in which Figure (a) uses 8 MPI processors with 4 OpenMP threads (32 CPU cores in total), and Figure (b) uses 27 MPI processors with 2 OpenMP threads (54 CPU cores in total). In these Figures, only XY dimensions are shown for simplicity.
For Case (a), the following commands are used:
$ export OMP_NUM_THREADS=4
$ mpirun -np 8 /home/user/genesis/bin/spdyn INP > md.log
In the log file, the user can see information about how many MPI processors and OpenMP threads are used for hybrid parallel calculation and how many domains and cells are constructed for the system. For Case (a), the log message looks like this:
Setup_Mpi_Md> Summary of Setup MPI number of MPI processes = 8 number of OpenMP threads = 4 total number of CPU cores = 32
Setup_Boundary_Cell> Set Variables for Boundary Condition domains (x,y,z) = 2 2 2 ncells (x,y,z) = 6 6 6
If “unexpected” number of MPI processors or OpenMP threads is shown, there might be an error in your command or batch scripts.
The user can specify domain numbers explicitly in the control file (domain_x, y, and z in the [BOUNDARY] section). For example, in Case (b) the following parameters and commands are used:
[BOUNDARY] type = PBC # [PBC] domain_x = 3 # number of domains in x dimension domain_y = 3 # number of domains in y dimension domain_z = 3 # number of domains in z dimension
$ export OMP_NUM_THREADS=2 $ mpirun -np 27 /home/user/genesis/bin/spdyn INP > md.log
Note that in this way total number of MPI processors must be identical to domain_x*domain_y*domain_z. Otherwise, the simulation stops immediately at the setup stage. If domain numbers are not specified in the control file, they are automatically determined at the beginning of the simulation according to the number of MPI processors. However, this automatic setting can work in the case MPI number is suitable to construct proper numbers of domain and cell.
The user can set “export OMP_NUM_THREADS=1” in hybrid MPI/OpenMP calculation, while it means flat MPI.
Due to specific algorithms implemented in spdyn (J. Jung et al., 2014 ), there is a strict rule for the number of cells in each domain, where the domain should be composed of more than 8 cells and at least 2 cells in each dimension. Thus, to use spdyn the target system should be large enough. The user should remember this rule, especcially, in the NPT simulation, because the box size can change during the simulation. In the NPT simulation, domain numbers are fixed to the initial values, while cell numbers can change and are adjusted to keep the cell size larger than pairlistdist. When the cell number in one dimension unfortunately becomes one, the simulation stops immediately because of the violation of the above rule. The user may often encounter this situation if the cell size is very close to pairlistdist and the cell number in one dimension is only two at the beginning of the MD simulation. To avoid such problems, the user may have to use smaller number of MPI processors (which makes larger domain) or shorter pairlistdist (making much cells in one domain), or reconstruct a larger system.