 Contact
ContactProgram
DAY-1 : Jan 29
| Time | Program |
|---|---|
| 9:00 - 9:20 |
Opening + Message from MEXT |
| 9:20 - 10:10 |
Keynote 1 Satoshi Matsuoka (RIKEN, R-CCS) |
| 10:10 - 10:30 |
Break |
| 10:30 - 11:05 |
Quantum Science Invited Talk Wibe Albert de Jong (Lawrence Berkeley National Laboratory) |
| 11:05 - 11:55 |
Quantum Science Kae Nemoto (OIST) Suguru Endo (NTT) |
| 11:55 - 13:30 |
Lunch Fugaku Tour B (Exhibition area, no application required) |
| 13:30 - 14:05 |
Science by Computing: Classical, AI/ML Invited Talk Jan Kosinski (EMBL, Hamburg) |
| 14:05 - 14:55 |
Science by Computing: Classical, AI/ML Bruno Adriano (Tohoku University) Marie Oshima (IIS, University of Tokyo) |
| 14:55 - 15:15 |
Break |
| 15:15 - 15:50 |
FS Invited Talk Eric Monchalin (Eviden) |
| 15:50 - 16:40 |
FS Masaaki Kondo (RIKEN, R-CCS) Takeshi Iwashita (RIKEN, R-CCS | Kyoto University) |
| 16:40 - 17:00 |
Group Photo |
| 17:00 - 18:20 |
Poster Session Reception hall (3rd floor) |
| 18:30 - 20:00 |
Reception Reception hall (3rd floor) |
DAY-2 : Jan 30
| Time | Program |
|---|---|
| 9:00 - 10:20 |
Fugaku Tour A (Computer room, application required) |
| 10:20 - 11:10 |
Keynote 2 Mikael Johansson (CSC Finland) |
| 11:10 - 11:45 |
Quantum computing Invited Talk Mitsuhisa Sato (RIKEN, R-CCS) |
| 11:45 - 12:10 |
Quantum computing Wataru Mizukami (Osaka University) |
| 12:10 - 13:45 |
Lunch Fugaku Tour B (Exhibition area, no application required) |
| 13:45 - 14:20 |
Science of Computing: Classical, AI/ML Invited Talk Michela Taufer (University of Tennessee) |
| 14:20 - 14:55 |
Science of Computing: Classical, AI/ML Invited Talk Rick Stevens (Argonne NL | U Chicago) |
| 14:55 - 15:20 |
Science of Computing: Classical, AI/ML Makoto Taiji (RIKEN, BDR) |
| 15:20 - 15:40 |
Break |
| 15:40 - 17:00 |
Panel Discussion |
| 17:00 - 17:10 |
Closing |
All oral presentations and panel discussion will be held in the conference room (3rd floor)
Program
- Keynote 1 (DAY-1 : Jan 29 9:20 - 10:10)
-
- Satoshi Matsuoka (RIKEN, R-CCS)
-
Computing for the Future at RIKEN R-CCS: AI for Science, Quantum-HPC Hybrid, and FugakuNEXT
-
At RIKEN R-CCS, the legacy of Fugaku, our flagship supercomputer, is just the beginning. We're embarking on an ambitious journey to redefine the landscape of high-performance computing, with a keen focus on societal impact and scientific innovation. Our roadmap includes several groundbreaking projects that promise to elevate our capabilities and contributions to unprecedented levels. Central to our strategy is the "AI for Science" initiative, a project that places artificial intelligence at the heart of scientific research. This endeavor aims to harness the power of AI to decipher complex data, accelerate discovery processes, and provide deeper insights across various scientific domains. By integrating AI with supercomputing, we're not just enhancing computational efficiency; we're transforming the very paradigm of scientific exploration. In parallel, we're excited about the development of "FugakuNEXT," the successor to Fugaku. This next-generation supercomputer will incorporate advanced technologies, including innovative memory solutions designed to drastically reduce the energy consumption associated with data movement, a critical challenge in scaling supercomputing capabilities. Moreover, our commitment to expanding the frontiers of computability extends to the realm of Quantum-HPC Hybrid computing. This pioneering project aims to merge the quantum computing's unique capabilities with the robust power of traditional high-performance computing, opening new avenues for solving previously intractable problems. Recognizing the importance of accessibility and flexibility in computing resources, we're also integrating our supercomputing assets with cloud platforms, notably AWS. This strategic move will democratize access to supercomputing power, enabling a broader range of researchers to tackle pressing global challenges with greater agility and scalability. Together, these initiatives represent RIKEN R-CCS's vision for the future—a future where supercomputing is not just about raw computational power, but about enabling a more profound understanding of the natural world, driving innovation, and contributing solutions to some of the most pressing issues facing humanity today.
- Quantum Science Invited Talk 1 (DAY-1 : Jan 29 10:30 - 11:05)
-
Session Chair: Takahito Nakajima (RIKEN, R-CCS)
- Wibe Albert de Jong (Lawrence Berkeley National Laboratory)
-
Towards practical applications on quantum computers
-
Quantum computing has the potential to develop as an experimental and computational platform for physics, chemistry, materials science, and biology. Considerable progress has been made in hardware, software and algorithms that allow us to probe practical applications with quantum computers, and make scientific discovery a reality. In this talk, I will discuss some of the recent developments in quantum computing algorithms to simulate the complex many-body systems common in physical sciences. To obtain reliable results from NISQ quantum computers, error mitigation, and reduction of computational complexity are essential. I will highlight some of our efforts to enable reliable simulations on quantum hardware.
- Quantum Science (DAY-1 : Jan 29 11:05 - 11:55)
-
Session Chair: Takahito Nakajima (RIKEN, R-CCS)
- Kae Nemoto (OIST)
-
Quantum Dynamics and Machine Learning
-
There has been a huge world-wide effort to find problems which noisy intermediate scale quantum (NISQ) processors can easily solve. However it turns out to be rather difficult to find practical problems such processors are really good at. In this talk, we will address this issue by asking ourselves a simple question: how should we ask questions to noisy quantum computers? We will first introduce the concept of quantum extreme reservoir computation (QERC), which can solve various classification problems with high accuracy using as few as ten qubits. Then we will detail the advantages and disadvantages of QERC and discuss how quantum dynamics classify input states.
- Suguru Endo (NTT)
-
Quantum algorithms based on post-processing: Quantum error mitigation and hybrid tensor networks
-
The computation ability of quantum computers catches a significant amount of attention; however, the scalability of quantum computers is still limited and also incurs a non-negligible effect of computation noise due to environmental interactions. In this talk, we explain the overview of methods to expand simulated quantum systems, i.e., hybrid tensor networks (HTNs) and quantum error mitigation (QEM) methods for error suppression. Then, we report our recent progress in these fields. For HTNs, we show how the transition matrices can be computed, which is necessary in material science and chemistry. Also, we report our formulation of noisy HTNs, which reflects the reality. For QEM, we introduce quite a general formalism called generalized quantum subspace expansion, which is a unified framework of quantum error mitigation methods. We show that this method even enables the simulation of larger quantum systems as well as mitigating noise.
- Science by Computing: Classical, AI/ML Invited Talk (DAY-1 : Jan 29 13:30 - 14:05)
-
Session Chair: Florence Tama (RIKEN, R-CCS)
- Jan Kosinski (EMBL, Hamburg)
-
Integrative structural biology in the era of accurate AI-based structure prediction
-
Macromolecular assemblies, comprising varied configurations of proteins and nucleic acids, are fundamental to biological processes. These assemblies vary in complexity, displaying configurations that range from simple dimers to intricate structures with numerous subunits. The elucidation of their structures is pivotal for decoding functional mechanisms and interactions. Integrative structural biology amalgamates complementary techniques, including electron microscopy, X-ray crystallography, chemical crosslinking, and computational modeling, to construct comprehensive structural representations of these assemblies. I will present our work on integrative computational modeling of macromolecular assemblies and how our approaches changed following the emergence of artificial intelligence structure prediction programs such as AlphaFold. Through real case examples, I will showcase the enhanced modeling pipelines and their applications in resolving complex biological structures.
- Science by Computing: Classical, AI/ML (DAY-1 : Jan 29 14:05 - 14:55)
-
Session Chair: Florence Tama (RIKEN, R-CCS)
- Bruno Adriano (Tohoku University)
-
Application of AI and physics-based modeling to enhance disaster science
-
One of the most important aspects, when a disaster happens is accurately understanding the intensity of the catastrophe in real time. This information will lead to efficient post-disaster response and relief efforts. The forecast system comprises rapid numerical simulation with a High-Performance Computing (HPC) Infrastructure. Modern machine learning models can learn complex patterns from large computed datasets and enhance HPC-based forecasting systems. Here, a fusion of AI algorithms and physics-based modeling for rapid prediction of disaster intensity is presented.
- Marie Oshima (IIS, University of Tokyo)
-
New perspective on a patient-specific blood flow simulation with a machine-learning technique for clinical applications
-
Since a patient-specific simulation uses medical image data such as CT or MRI, quantifying an impact of uncertainties in medical images on simulated quantities is an essential task to obtain reliable results for clinical applications. In general, uncertainty quantification requires a large number of case studies to investigate the effects of uncertainties in a probabilistic manner. Thus, a machine-learning approach is an effective way to conduct quantification of uncertainties. The uncertainty quantification will be presented to investigate a risk of CHS (Cerebral Hyperfusion Syndrome) conditions using patient-data.
- Feasibility Study Invited Talk (DAY-1 : Jan 29 15:15 - 15:50)
-
Session Chair: Kentaro Sano (RIKEN, R-CCS)
- Eric Monchalin (Eviden)
-
Will HPC be a next decade disruptor, or will it be disrupted?
-
Supercomputing is at the forefront to solve societal, academic, and business challenges such as climate change, energy, decarbonation, sustainability, smart everything (cities, mobility, agriculture, medicine, manufacturing and so on), and many others. Supercomputing thus plays an essential role for any continent, economical space or nation which wants to tackle these numerous challenges and strengthen its leadership and sovereignty. However, the future of the HPC ecosystem itself is a daunting challenge. It has to overcome human and technology roadblocks to unlock its long-term potential, which includes, amongst others:
- Making scientific education and expertise great again,
- Fast energy transition to electricity foreshadowing a mismatch between supply and demand,
- Slowdown of Moore’s law,
- GPU trend favoring the performances of deep learning workloads.
The European Union, with its long and strong history in mathematics and science, can draw on its own strengths to free itself from these obstacles. Relying on its EuroHPC Joint Undertaking initiative, it is developing long-term and sovereign supercomputing technologies that can compete on the global HPC market. These key ingredients will support the European Union to equip itself with a world-class supercomputing infrastructure during the course of the decade and beyond.
- Feasibility Study (DAY-1 : Jan 29 15:50 - 16:40)
-
Session Chair: Kentaro Sano (RIKEN, R-CCS)
- Masaaki Kondo (RIKEN, R-CCS)
-
Introduction of the Feasibility Study Project for Next-Generation Supercomputing Infrastructures
-
The demand of high-performance computing is growing as it becomes an indispensable framework for science and AI. It is already time to consider architecture, system software, and applications for next-generation supercomputer systems beyond exascale. There are many technical challenges towards development of next generation systems as we are now facing the end of Moore's law. Together with various domestic and international partners, we have been conducting a feasibility studies on next-generation supercomputing infrastructures as a part of a national project by the Ministry of Education, Culture, Sports, Science and Technology (MEXT) Japan. In this talk, we introduce an overview and the recent status of Riken's feasibility study as a system research team.
- Takeshi Iwashita (RIKEN, R-CCS | Kyoto University)
-
Introduction of application group activities of RIKEN FS team and a prospective on next-generation applications
-
In this talk, activities of the RIKEN FS application group since 2022 are introduced. A plan for 2024 of the group is also explained. Then the speaker's personal opinion for next generation applications and expected features for computing systems. His latest research result of a linear iterative solver for GPUs is also briefly introduced.
- Keynote 2 (DAY-2 : Jan 30 10:20 - 11:10)
-
Session Chair: Nobuyasu Ito (RIKEN, R-CCS)
- Mikael Johansson (CSC Finland)
-
Setting up a distributed HPC+QC network: The nitty-gritty details
-
Despite the potential superior performance of quantum computers for some tasks, they rely on traditional computers for various tasks. With increasing performance on the quantum computing side comes an increased need for matching classical computing power. An efficient HPC+QC integration provides a two-way feedback loop, where HPC systems gain from a QC component and quantum computers are enhanced by supercomputing. Setting up an HPC+QC infrastructure is far from trivial, when the goal is more than trivial functionality and performance. Here, I will discuss different aspects of the required components, ranging from user authentication, co-scheduling, and data processing at different stages of the computational workflows. Compared to pure HPC infrastructure, QC brings added complexity through the scarcity of resources and the extreme heterogeneity of user base. End-users need access to several different implementations of quantum-accelerated supercomputing. The distributed LUMI-Q concept will serve as an example and basis for a general discussion.
- Quantum Computing Invited Talk (DAY-2 : Jan 30 11:10 - 11:45)
-
Session Chair: Nobuyasu Ito (RIKEN, R-CCS)
- Mitsuhisa Sato (RIKEN, R-CCS)
-
Quantum HPC hybrid computing platform project in RIKEN R-CCS
-
As the number of qubits in advanced quantum computers is getting larger over 100 qubits, demands for the integration of quantum computers and HPC are gradually growing. RIKEN R-CCS has been working on several projects to build a platform which integrates quantum computers and HPC together. Recently, we have started a new project funded by NEDO titled “Research and Development of quantum-supercomputers hybrid platform for exploration of uncharted computable capabilities”. In this project, we are going to design and build a quantum-supercomputer hybrid computing platform which integrates different kinds of quantum computers, IBM and Quantinuum, with supercomputers including Fugaku. In this talk, the overview and plan of the QC-HPC hybrid computing platform projects in R-CCS will be presented.
- Quantum Computing (DAY-2 : Jan 30 11:45 - 12:10)
-
Session Chair: Nobuyasu Ito (RIKEN, R-CCS)
- Wataru Mizukami (Osaka University)
-
Development of quantum software at the quantum research center QIQB of Osaka University and its application to chemical problems
-
In recent years, quantum computers have undergone rapid development. Our institute, the Center for Quantum Information and Quantum Biology (QIQB) at Osaka University, has been organizing a research hub for quantum software in Japan, developing a full stack of software required for their use. This talk will first give an overview of software development for quantum computers at QIQB. We will then present the challenges and our efforts in applying quantum computing to chemistry, a field expected to be a promising application of this technology.
- Science of Computing: Classical, AI/ML Invited Talk (DAY-2 : Jan 30 13:45 - 14:20)
-
Session Chair: Mohamed Wahib (RIKEN, R-CCS)
- Michela Taufer (University of Tennessee)
-
Analytics4NN: Accelerating Neural Architecture Search through Modeling and High-Performance Computing Techniques
-
This talk addresses challenges and innovations in Neural Architecture Search (NAS) within high-performance computing. Focusing on the substantial computational demands of designing neural network (NN) architectures, we present Analytics4NN, a unified solution combining advanced modeling and high-performance computing techniques to enhance NAS efficiency. Analytics4NN introduces a novel fitness prediction engine alongside a composable workflow. It leverages parametric modeling for early fitness prediction of NNs, seamlessly integrating with existing NAS methods to form more flexible and efficient workflows. This strategy enables the early termination of less promising NNs, optimizing the use of computational resources and increasing the evaluation scope of NN models. Demonstrated on the Summit supercomputer, Analytics4NN shows a remarkable increase in throughput, up to 7.1 times, and a reduction in training time by as much as 5.3 times across diverse benchmark datasets and three state-of-the-art NAS implementations. Additionally, Analytics4NN's approach to distributed training and rigorous documentation significantly aids in the efficient design of NNs. Applied to a dataset generated by an X-ray Free Electron Laser (XFEL) experiment simulation, it reduced training time by up to 37%. It decreased the required training epochs by up to 38%. Analytics4NN represents a significant leap in the scalability and efficiency of NN design for scientific computing, effectively accelerating NAS by combining cutting-edge modeling with robust, high-performance computing techniques.
- Science of Computing: Classical, AI/ML Invited Talk (DAY-2 : Jan 30 14:20 - 14:55)
-
Session Chair: Mohamed Wahib (RIKEN, R-CCS)
- Rick Stevens (Argonne NL | U Chicago)
-
The Decade Ahead: Building Frontier AI Systems for Science and the Path to Zettascale
-
The successful development of transformative applications of AI for science, medicine and energy research will have a profound impact on the world. The rate of development of AI capabilities continues to accelerate, and the scientific community is becoming increasingly agile in using AI, leading to us to anticipate significant changes in how science and engineering goals will be pursued in the future. Frontier AI (the leading edge of AI systems) enables small teams to conduct increasingly complex investigations, accelerating some tasks such as generating hypotheses, writing code, or automating entire scientific campaigns. However, certain challenges remain resistant to AI acceleration such as human-to-human communication, large-scale systems integration, and assessing creative contributions. Taken together these developments signify a shift toward more capital-intensive science, as productivity gains from AI will drive resource allocations to groups that can effectively leverage AI into scientific outputs, while other will lag. In addition, with AI becoming the major driver of innovation in high-performance computing, we also expect major shifts in the computing marketplace over the next decade, we see a growing performance gap between systems designed for traditional scientific computing vs those optimized for large-scale AI such as Large Language Models. In part, as a response to these trends, but also in recognition of the role of government supported research to shape the future research landscape the U. S. Department of Energy has created the FASST (Frontier AI for Science, Security and Technology) initiative. FASST is a decadal research and infrastructure development initiative aimed at accelerating the creation and deployment of frontier AI systems for science, energy research, national security. I will review the goals of FASST and how we imagine it transforming the research at the national laboratories. Along with FASST, I’ll discuss the goals of the recently established Trillion Parameter Consortium (TPC), whose aim is to foster a community wide effort to accelerate the creation of large-scale generative AI for science. Additionally, I’ll introduce the AuroraGPT project an international collaboration to build a series of multilingual multimodal foundation models for science, that are pretrained on deep domain knowledge to enable them to play key roles in future scientific enterprises. RIKEN and R-CCS are key partners in the TPC and AuroraGPT projects.
- Science of Computing: Classical, AI/ML (DAY-2 : Jan 30 14:55 - 15:20)
-
Session Chair: Mohamed Wahib (RIKEN, R-CCS)
- Makoto Taiji (RIKEN, BDR)
-
Outline of RIKEN’s AI for Science project and the development of the strong scaling accelerator
-
In this talk, I will talk on two topics. The first one is AI for Science project “TRIP-AGIS” that will start from this year. The aim of the project is developments and applications of multimodal foundation models for science. We especially focus on life science and material science, and the project includes (1) the generations of multimodal data by advanced measurements (2) developments of multimodal foundation models using HPC and (3) researches on autonomous research system using foundation models and robotics / simulations. We will also explore computational aspects for training and inference of large-scale AI models from the viewpoints of processor architecture, software and application pipelines.
The second topic is the development of strong-scaling accelerator for MD simulations. We are currently developing MDGRAPE-5, a special-purpose computer system for MD using FPGA. It has a hardware support for middle-grain data-flow processing to minimize latencies in calculation flow. We will describe its outline and future possibilities of strong-scaling accelerators.
- Panel Discussion (DAY-2 : Jan 30 15:40 - 17:00)
-
Panel Discussion: Synergy between Classical Computing, Quantum Computing, and AI: Current state, challenges, and future prospects
Moderator: Michela Taufer (University of Tennessee)
Panelists:
- Rick Stevens (Argonne NL | U Chicago)
- Kae Nemoto (OIST)
- Eric Monchalin (Eviden)
- Makoto Taiji (RIKEN, BDR)
List of Accepted Posters
- 2Randomized-HOTRG and minimally-decomposed TRG
Katsumasa Nakayama (RIKEN R-CCS)* - In this poster, we introduce the cost reduction method for the higher-order tensor renormalization group (HOTRG) and its extension. Any TRG methods based on the singular value decomposition (SVD) as the approximation of the decomposition and contraction. The Randomized-SVD is well-known method to reduce the cost, and we apply it to the HOTRG as the approximation of the contraction. We also introduce further cost reduction method using low-order tensor representation called minimally decomposed TRG. All of these methods achieve the comparable precision compare to the HOTRG, with the much less computational cost.
- 3Toward 3D precipitation nowcasting by fusing NWP-DA-AI: application of adversarial training
Shigenori Otsuka (RIKEN R-CCS)*; Takemasa Miyoshi (RIKEN R-CCS) -
Recent advances of deep learning allowed us to seek for new data-driven algorithms to predict precipitation based on past observations by weather radars. In parallel, high-end supercomputers enabled us to perform “big data assimilation,” rapidly-updated numerical weather prediction at high spatiotemporal resolution by assimilating dense and frequent observations such as the Phased Array Weather Radar (PAWR) (e.g., Miyoshi et al. 2016 a, b, Honda et al. 2022a, b). In conventional precipitation nowcasting, blending of numerical weather prediction and extrapolation-based nowcasting is known to outperform either of these (e.g., Sun et al. 2014).
We have been testing a convolutional long short-term memory (ConvLSTM, Shi et al. 2015) - based neural network. Recently, an adversarial training is considered a promising technique for deep learning-based precipitation nowcasting to avoid blurring effect (Ravuri et al. 2021). Therefore, we applied an adversarial training to a three-dimensional extension of ConvLSTM with PAWR. Preliminary results indicate that the use of adversarial loss increases small-scale features compared to thetraining without the adversarial loss. In future, a numerical weather prediction output will be fed to the network to combine it with a deep learning-based prediction in a nonlinear manner. - 4Mathematical analysis of the ensemble transform Kalman filter for chaotic dynamics with multiplicative inflation
Kota Takeda (RIKEN R-CCS)*; Takashi Sakajo (Kyoto University) -
Data assimilation is a statistical method used for estimating the hidden state of a system
over time, also known as a filtering problem. It outlines the two primary steps in a data assimilation
cycle: prediction and analysis. In the prediction step, model dynamics propagate the filtering
distribution, while in the analysis step, new observations are incorporated into the estimation. We
focus on studies of the ensemble Kalman filter (EnKF), usually applied for nonlinear dynamics.
EnKF employs an empirical distribution of samples, termed an ensemble, to estimate nonlinear
propagation. It is categorized into two algorithms based on the method of producing the analysis
ensemble: the perturbed observation (PO) method, a simpler but stochastic approach, and the
ensemble transform Kalman filter (ETKF), a more complex but deterministic method.
A key challenge in EnKF is the underestimation of the covariance matrix due to the finite size ensemble, leading to unstable filtering. Ad-hoc techniques like additive and multiplicative covariance inflations are used to address this. Kelly et al. established a uniform-in-time error bound for the PO method using additive inflation in dissipative chaotic dynamics, including the two- dimensional Navier-Stokes equations. However, the ETKF, due to its complexity, has not been analyzed similarly. Thus, our study aims to obtain an error bound for the ETKF in chaotic dynamics with multiplicative inflation. - 5Exploring the flavor structure of quarks and leptons with reinforcement learning
Satsuki Nishimura (Kyushu University)*; Coh Miyao (Kyushu University); Hajime Otsuka (Kyushu University) - The Standard Model of particle physics describes the behavior of elementary particles with high accuracy, but there are many problems. For example, the Standard Model does not explain the background of mass hierarchy of matter particles. In addition, the difference of flavor mixing between quarks and leptons is also mysterious. Then, we propose a method to explore the flavor structure of quarks and leptons with reinforcement learning, which is one type of machine learning methods. As a concrete model, we focus on the Froggatt-Nielsen model, and utilize a basic value-based algorithm for the model with U(1) flavor symmetry. By training neural networks on the U(1) charges of quarks and leptons, the agent finds 21 models to be consistent with experimentally measured masses and mixing angles of quarks and leptons. In particular, we define the intrinsic values to evaluate consistency with experimental data, and intrinsic values of normal ordered neutrino masses tend to be larger than that of inverted ordering. In other words, the normal ordering is well fitted with the current experimental data in contrast to the inverted ordering. Moreover, a specific value of effective mass for the neutrinoless double beta decay and a sizable leptonic CP violation induced by an angular component of flavon field are predicted by autonomous behavior of the agent. Thus, our finding results indicate that the reinforcement learning can be a new method for understanding the flavor structure. The reference is JHEP12(2023)021 (arXiv:2304.14176 [hep-ph]).
- 6TEZip Integration in LibPressio: Bridging Dynamic Application Capabilities with a Static C Environment
Amarjit Singh (RIKEN)*; Kento Sato (RIKEN) -
Big data refers to wide datasets characterized by complex structures, requiring advanced
methods for collection, analysis, and subsequent processing. Research in this domain investigates
the details of handling considerable data volumes, with a focus on big data analysis. Accurate
analysis and execution of data are essential in big data computation. The exponential growth of
big data highlights the importance of studying and evaluating its various behavioral patterns.
Scientific instruments and data analytics applications deal with the challenges posed by big
datasets, which present difficulties in terms of mobility, storage, and processing. Compression,
whether lossless or lossy, develops as a possible solution to tackle these issues. Numerous
applications based on compression techniques, seek to reduce data volumes.
TEZip stands out as a DNN-driven compressor for processing time-evolving data. Functioning on the principle of prediction, TEZip predicts the succeeding data frame passing information from the preceding frame. It then efficiently stores the variance between this prediction and the actual next frame as part of its compression strategy. On the other hand, LibPressio serves as a comprehensive abstraction layer encompassing various compressors.
Facilities like SPring-8, LCLS-II, SNS, and various other instruments rely on software developed in C and C++, generating extensive amounts of time-evolving data at a rapid pace. TEZip, a deep neural network (NN)-based compressor designed for compression of time-evolving data, is implemented in Python, posing challenges for seamless utilization and portability to C++. This challenge extends to other compressors, such as LinLogCompress.jl in Julia and those leveraging PyTorch/TensorFlow, for instance, the autoencoder based compressor.
To seamlessly integrate TEZip and LibPressio, a robust bridge needs to be constructed between Python and C++ environments. This undertaking is driven by the dual goals of ensuring effective collaboration between the two environments and prioritizing efficiency, especially in the realm of high-performance computing. We’ve done the integration initial TEZip and Libpressio to increase the usability. Metrics can be generated for TEZip compression and decompression via LibPressio. TEZip compression ratios are higher than all other compressors. TEZip’s compression ratio (Error Bound 1e-06) for Hurricane Isabel is 128 which is 2.4 times greater than the leading SZ3’s, 52.8. - 7Single-reference coupled cluster theory for systems with strong correlation extended to excited states
Shota Tsuru (RIKEN R-CCS)*; Stanislav Kedžuch (RIKEN R-CCS); Takahito Nakajima (RIKEN R-CCS) -
Coupled cluster (CC) theory has size-extensivity and is regarded as “gold standard” of
electronic structure theory based on wave functions. Nevertheless, conventional CC theory
referenced to a single Slate determinant of the restricted Hartree-Fock (RHF) theory is troublesome
for systems with strong correlations, such as molecules in transition states and systems with
partially filled d-or f-orbitals, due to instability of the reference. Although multireference (MR)
CC is simple idea as adaptation of CC theory to systems with strong correlations, some technical
difficulties inherent to MR-CC hamper formulation of a theory applicable to general systems and
the extension to excited states.
Once spin-singlet and triplet pairs have been decoupled and the spin-triplet pairs have been removed in double electronic excitation of CCSD referenced to a single Slater determinant of the unrestricted Hartree-Fock (UHF) method, the stability and symmetry dilemma is solved and the modified CCSD method correctly behaves in dissociation limits and transition states. The CCSDlevel accuracy, which is once lost due to removal of the spin-triplet pairs double excitation, is recovered by recoupling double excitations of both the spin multiplicity. This modified CCSD theory named FSigCCSD implicitly describes static correlation related to the spin-triplet instability of the RHF reference employing the algorithms developed for the conventional CCSD theory.
This time, we have extended the FSigCCSD theory to excited states in the equation-of-motion scheme. The present work is a step towards a dynamics simulation method applicable to general chemical processes. - 8Parameterization of lipid-protein interactions in the iSoLFv2 model
Diego Ugarte (RIKEN R-CCS)*; Shoji Takada (Kyoto University); Yuji Sugita (RIKEN R-CCS,RIKEN BDR, RIKEN CPR) - Transmembrane proteins play essential roles in several biological processes. A possible regulation mechanism for these proteins is their selective partitioning inside lipid domains. However, depending on the study target, performing all-atom (AA) simulations for studying transmembrane protein partitioning requires unreachable simulation times, even using modern hardware. In this study, we present the current state of our latest parameterization of the lipidprotein interactions for the recently developed iSoLFv2 coarse-grained (CG) model. This new parameterization will enable the usage of iSoLFv2 together with the AICG2+ and HPS CG protein model in the GENESIS molecular dynamics software to perform large-scale simulations of biological membrane systems and membrane-regulated phenomena.
- 9Potential for improving ensemble weather forecasting using mixed floating-point numbers
Tsuyoshi Yamaura (RIKEN R-CCS)* - The purpose of this study is to improve forecast accuracy by using low-precision floating-point arithmetic to prevent ensemble spread shrinkage when performing ensemble weather forecasting. Low-precision floating-point arithmetic is reproduced using a software emulator developed to allow the bit length of the mantissa of floating-point numbers to be adjusted in one-bit increments. First, we compared and evaluated ensemble methods using low-precision floating-point arithmetic according to the initial value ensemble method and the model ensemble method. The low-precision floating-point ensemble method was found to be unsuitable for the initial value ensemble method because it acts like a Gaussian noise and the ensemble spread does not expand much. The model ensemble method was found to have a similar ensemble spread as the conventional ensemble method. In order to objectively evaluate the ensemble method using low-precision floating-point arithmetic in accordance with the model ensemble method, ensemble forecasting experiments were conducted in combination with the conventional ensemble method. As a result, the combined ensemble forecast had a higher objective value than the ensemble forecast using only the conventional ensemble method and the ensemble method using lowprecision floating-point arithmetic. The reasons why the ensemble forecasts were higher when incorporating low-precision floating-point ensemble methods are considered: weather forecast models are not able to reproduce weather phenomena below the grid scale due to their low spatiotemporal resolution, and some models incorporate statistical assumptions to reduce computational load, which suppress the random nature of weather phenomena than actual weather events. On the other hand, ensemble methods using low-precision floating-point arithmetic can compensate for this randomness, and thus are expected to have higher evaluation values. Although the theoretical validation of this study was conducted using a software emulator, this suggests that low-precision floating-point arithmetic can also be implemented in hardware by using FPGAs, which may allow for faster operations without compromising forecast accuracy in ensemble forecasting.
- 10Improving the short-range predictability of severe convective storms using a 1000-member ensemble Kalman filter with 30-second update using multi-parameter phased array weather radar observations
James Taylor (RIKEN R-CCS)*; A. Amemiya (RIKEN R-CCS); S. Otsuka (RIKEN R-CCS); T. Honda (RIKEN R-CCS); Y. Maejima (RIKEN R-CCS); T. Miyoshi (RIKEN R-CCS) - High precision forecasting of convective weather systems remains extremely challenging owing to their highly non-linear, rapid evolution and involving of small-scale processes and fine-scaled features. Here, we present results of 30-minute precipitation forecasts for a convective system that passed over Tokyo generated from an experimental real-time NWP modeling system that uses a 1000-member ensemble Kalman filter with a 30-second update using observations from a multi-parameter phased array weather radar (MP-PAWR). The system successfully predicted rapid changes to the storm’s structure and intensity, and accurately predicted the location of heaviest rainfall up to 30-minute lead times. A comparative analysis of forecasts initialized during a period when the convective system was undergoing development showed the NWP model consistently outperforming nowcasts generated from an advection-based model at up to 30-minute lead times. The 30-second update was found to be crucial for improving rain forecasts through increased moistening and upward motion in the storm environment.
- 11Power Consumption Metric on Heterogeneous Memory Systems
Andres Xavier Rubio Proano (Riken R-CCS)*; Kento Sato (Riken R-CCS) -
Over the years, the architecture of supercomputers has evolved to support an increasing
number of applications aimed at addressing problems of interest to humanity. This evolution has
recently embraced the concept of heterogeneity, taking into account two aspects. Firstly, in
processing, the utilization of various processing elements such as the Central Processing Unit
(CPU), Graphic Processing Unit (GPU), and other accelerators coexisting within the same machine.
Secondly, on the memory-storage side, memory systems now incorporate more than one type of
memory, giving rise to Heterogeneous Memory Systems (HMS). For instance, in Sapphire Rapids,
one can observe the support of High Bandwidth Memory (HBM), non-volatile memory (NVM),
and also Dynamic Random-Access Memory (DRAM). This complexity complicates current and
future applications, given the trend toward more memory-bound applications. Those applications
utilize the memory system in ways that may not appropriately leverage the type of memory when
dealing with HMS.
Memory devices exhibit different properties that allow for better performance depending on the nature of the applications, such as latency, bandwidth, capacity, persistence, and power consumption. This research is specifically focused on power consumption, motivated by scenarios requiring the use of memory with the lowest power consumption target or a balance between power consumption and application performance. All of this is within the context of High-Performance Computing (HPC) power capping policies, necessitating different ways of utilizing hardware. In fact, data center runs complex simulation e.g. weather forecasting. In these applications, the interplay between computational power and power consumption efficiency becomes pivotal. Failure to manage power consumption effectively may result in exceeding power caps, leading to performance throttling or, in extreme cases, system shutdowns. Moreover, in environments where energy costs are a significant concern, understanding power consumption allows organizations to optimize operational expenses. By strategically utilizing different types of memory with varying power characteristics, it becomes possible to strike a balance between computational performance and power consumption efficiency.
For developers, the task of programming new applications or adapting existing ones requires a comprehensive understanding of the memory system. Without a specific strategy, this task can be highly complex, depending on the conditions under which the applications need to run. It is pertinent for developers to prepare their applications to effectively handle at least the main HMS setups. For this reason, we argue that every developer should possess a basic understanding of HMSs in terms of simple and accessible metrics such as bandwidth, latency, capacity, data persistence, power consumption, etc. Crucially, developers need to know how much memory power their applications will consume in a given memory system. This knowledge becomes vital in situations where executions need to be performed in minimal power consumption mode or when balancing power consumption and performance is crucial.
To understand memory performance, we have devised a methodology to characterize power consumption within an HMS, enabling their ranking. Initially, we simplified the exposure of the memory system to applications using hwloc, the de facto standard for discovering hardware topology. Subsequently, we employed pro ling techniques for applications. Our challenge has been that performance counters often only allow the exposure of memory socket power values, meaning we could not differentiate between the power values of, for example, DRAM or NVM separately. To address this issue, our strategy involves binding the entire process to the corresponding memory target and then, by considering idle power values, deducing that the corresponding value corresponds to a specific memory type.
For this, we have extensively tested our strategy in a cluster with heterogeneous memory by using different benchmark applications where we were able to rank our memory system by application. This information is crucial in the path of adapting, porting and developing applications that seek to use hardware resources depending of the system limitations. Our strategy jumps the limitation of having systems with performance counters that cannot differentiate in between memory kinds. - 12Impact of atmospheric forcing on SST biases in the LETKF-based Ocean Research Analysis (LORA)
Shun Ohishi (RIKEN R-CCS)*; Takemasa Miyoshi (RIKEN R-CCS); Misako Kachi (JAXA EORC) -
Various ocean analysis products have been produced by research institutions and used
for geoscience research. In the Pacific region, to our best knowledge, there are four high-resolution
regional analysis datasets [JCOPE2M (Miyazawa et al. 2017) and FRA-ROMS II (Kuroda et al.
2017) with 3D-VAR; NPR-4DVAR (Hirose et al. 2019); and DREAMS with Kalman filter (Hirose
et al. 2013)], but there is no ensemble Kalman filter (EnKF)-based analysis dataset.
Recently geostationary satellites have provided sea surface temperatures (SSTs) at higher spatiotemporal resolution than before. To take advantage of such observations, we have developed an EnKF-based ocean data assimilation system with a short assimilation interval of 1 day and demonstrated that the combination of three schemes [incremental analysis update (IAU; Bloom et al. 1996), relaxation to-prior perturbation (RTPP; Zhang et al. 2004), and adaptive observation error inflation (AOEI; Minamide and Zhang 2017)] significantly improves geostrophic balance and analysis accuracy (Ohishi et al. 2022a, b). With the recent enhancement of computational resources, we have developed higher-resolution ocean data assimilation systems sufficient to resolve fronts and eddies and produced ensemble analysis products in the western North Pacific (WNP) and Maritime Continent (MC) regions referred to as the LETKF-based Ocean Research Analysis (LORA)-WNP and -MC, respectively (Ohishi et al. 2023). The validation results show that the LORA has sufficient accuracy for geoscience research and various applications. However, high SST biases over 1.0 °C are detected near the coastal regions, where coarse atmospheric reanalysis datasets might not accurately capture the coastlines. Therefore, this study aims to investigate the impacts of atmospheric forcing on the nearshore SST biases and to examine the mechanisms of the improvement of the SST biases.
We have conducted sensitivity experiments of the atmospheric forcing using atmospheric reanalysis datasets from JRA-55 (Kobayashi et al. 2015) and JRA55-do (Tsujino et al. 2018) with horizontal resolution of 1.25° and 0.5°, respectively, which are referred to as the JRA55 and JRA55do runs. We note that the setting of the JRA55 run is the same as Ohishi et al. (2023) and that the JRA55-do is a surface atmospheric dataset for driving ocean-sea ice models and is created by adjusting JRA-55 toward high-quality reference datasets such as CERES-EBAF-Surface_Ed2.8 data (Kako et al. 2013).
The validation results show that the SST biases and RMSDs relative to assimilated satellite and independent in-situ coastal data are improved in the JRA55do run, especially near the coastal regions. The mixed layer temperature budget analysis indicates that stronger latent heat release by nearshore stronger wind speed and weaker downward shortwave radiation by the adjustment in JRA55do is the main cause of the improvement of the high SST biases in September-October. This results in further improvement in November-January, because the smaller absolute innovation reduces the frequency of the AOEI application. Consequently, cooling in the analysis increments is stronger in the JRA55do run. This study indicates the importance of the quality of atmospheric forcing for EnKF-based ocean data assimilation systems. It would be important to keep access to surface atmospheric datasets for driving ocean-sea ice models. - 13Parametrized quantum circuit for weight-adjustable quantum loop gas
Rongyang Sun (RIKEN R-CCS)*; Tomonori Shirakawa (RIKEN R-CCS); Seiji Yunoki (RIKEN R-CCS) - Topological quantum phases emerge from correlated quantum many-body systems containing novel features such as nontrivial entanglement structure and mutual statistics. However, the co-emerged exponential computational complexity strongly hampers the research of these systems using classical computers. Present booming quantum computing techniques offer a new way to investigate these challenging systems: the quantum simulation approach. Combining current available noise intermediatescale quantum (NISQ) devices with variational quantum eigen solver (VQE) algorithm to solve quantum many-body problems has attracted extensive attention. In this poster presentation, I will explain how to realize scalable VQE calculation in the intrinsic topologically ordered phase by designing problem specified scalable parameterized quantum circuit (PQC) Ansatze. We construct a real-device-realizable PQC that can represent a weight-adjustable quantum loop gas (denoted as PLGC Ansatz) to study the toric code model in an external magnetic field (named TCM, non-exactly solvable) and obtain accurate ground states (see Fig. 1) of the system with different sizes in the VQE simulation on classical computers.
- 14Python vs C on the A64FX processor : A case study from quantum circuit synthesis
Miwako Tsuji (RIKEN R-CCS)*; Sahe Ashhab (National Institute of Information and Communications Technology); Kouichi Semba (The University of Tokyo); Mitsuhisa Sato (RIKEN R-CCS) -
Python is a widely adopted programming language in scientific and high-performance
computing. Since Python is an interpreted language, the performance characteristics of Python are
different from traditional HPC languages such as C and Fortran. Python code is often slower than
equivalent code in other languages. Several Python modules, such as NumPy and Scipy, use
optimized and compiled mathematical libraries internally to fill the performance gap.
In this paper, we study the performance of a Python quantum circuit synthesis code on the A64FX processor and compare it with an equivalent code written in C. The quantum circuit synthesis algorithm that we use is a random search technique to find quantum gate sequences that implement perfect quantum state preparation or unitary operator synthesis with arbitrary targets. This approach is based on the recent discovery that a large multiplicity of quantum circuits achieve unit fidelity in performing the desired target operation, which means that the quantum circuit synthesis problem has a large number of solutions and a random search approach is well suited for this problem. The code generates a certain number of random circuits, typically 100 circuits, and optimizes single-qubit rotation parameters by a modified version of the gradient ascent pulse engineering (GRAPE) algorithm. The GRAPE algorithm is an iterative method, and each iteration involves numerous double-complex matrix-matrix operations, i.e. zgemm operations. Firstly, we evaluate the performance of zgemm operations in Python and C by changing the size of the matrix and the number of threads. Python and C zgemm codes use Scientific Subroutine Library II (SSL2), a thread-safe numerical calculation library highly optimized for the A64FX processor.
Then, we evaluate the performance of the quantum circuit synthesis codes written in C and Python by changing the number of qubits and the number of threads. In our experiments, the performance of the Python code is slightly worse than that of the C code in a single-thread execution. Increasing the number of threads makes the gap larger since computations other than zgemm in the Python code become dominant. - 15Streamlined data analysis in Python
David A Clarke (University of Utah); Jishnu Goswami (RIKEN RCCS)* -
In this poster, we will present our publicly available AnalysisToolbox
(https://github.com/LatticeQCD/AnalysisToolbox) for statistical data analysis in Python and how
this can be run on supercomputers by overcoming the slowness of the scripting language. Python
is an exceptionally user-friendly language, ideal for data analysis, largely due to its accessibility
and robust, well-maintained libraries such as NumPy and SciPy.
However, in the realm of data analysis, these libraries lack some necessary functionalities. Additionally, scripting languages generally run slower than compiled languages. To address these issues partially, we introduce Analysis-Toolbox. This suite of Python modules is specifically designed to streamline data analysis for physics problems. Key features of AnalysisToolbox are, General mathematics: Numerical differentiation, convenience wrappers for SciPy numerical integration and solving IVPs; General statistics: Jackknife, bootstrap, Gaussian bootstrap, error propagation, estimate integrated autocorrelation time, and curve fitting with and without Bayesian priors. The math and statistics methods are generally useful, independent of physics contexts; General physics: Unit conversions, critical exponents for various universality classes, physical constants, Ising model in arbitrary dimensions; Lattice QCD: Continuum-limit extrapolation, Polyakov loop observables, SU(3) gauge fields, reading in gauge fields, and the static quarkantiquark potential. These methods rather target lattice QCD; QCD physics: Hadron resonance gas model, QCD equation of state, and the QCD beta function. These methods are useful for QCD phenomenology, independent of lattice QCD contexts. - 16Unleashing CGRA's Potential for HPC
Boma Anantasatya Adhi (RIKEN R-CCS)*; Emanuele Del Sozzo (RIKEN R-CCS); Carlos Cortes (RIKEN R-CCS); Tomohiro Ueno (RIKEN R-CCS); Kentaro Sano (RIKEN R-CCS) - This poster highlights our previous and future design-space exploration effort to optimize our Coarse-Grained Reconfigurable Array (CGRA) architecture for HPC, i.e., intraCGRA interconnect optimization, FMA and transcendental operation on CGRA, programmable buffer, systolic-array style execution on CGRA, predication support, and FPGA based emulation on actual HPC environment.
- 17The effect of fermions on the emergence of (3+1)-dimensional space-time in the Lorentzian type IIB matrix model
Konstantinos N. Anagnostopoulos (NTUA); Takehiro Azuma (Setsunan University)*; Kohta Hatakeyama (Kyoto University); Mitsuaki Hirasawa (Universita degli Studi di Milano-Bicocca); Jun Nishimura (KEK & SOKENDAI); Stratos Papadoudis (NTUA); Asato Tsuchiya (Shizuoka University) - The type IIB matrix model, also known as the IKKT model, is a promising candidate for the non-perturbative formulation of string theory. Its Lorentzian version, in which indices are contracted using the Lorentzian metric, has a sign problem stemming from eiS in the partition function (where S is the action). It has turned out that the Lorentzian version is equivalent to the Euclidean one, in which the SO(10) rotational symmetry is spontaneously broken to SO(3), under the Wick rotation as it is. This leads us to add a Lorentz-invariant mass term to the Lorentzian version of the type IIB matrix model. To cope with the sign problem, we perform numerical simulations based on the complex Langevin Method (CLM), relying on stochastic processes for complexified variables. In order to avoid the “singular drift problem”, we add a fermionic mass term. To compensate for the reduced effect of fermions by the aforementioned fermionic mass term and mimic the SUSY cancellation, we introduce parameters to control the quantum fluctuations of the bosonic matrices, so that the (9 - d) spatial directions are suppressed and the emergent space is restricted to at most d dimensions (d = 4, 5, 6, 7, 8). We observe a (3+1)- dimensional space-time, with 3 out of the d spatial dimensions expanding at late time.
- 18Towards PowerAPI and KVS-based Energy-Aware Image-based In-Situ Visualization on the Fugaku
Razil Bin Tahir (University of Malaya)*; Jorji Nonaka (RIKEN R-CCS); Ken Iwata (Kobe University); Taisei Matsushima (Kobe University); Naohisa Sakamoto (RIKEN R-CCS); Chongke Bi (Tianjin university); Masahiro Nakao (RIKEN R-CCS); Hitoshi Murai (RIKEN R-CCS) -
Energy efficiency has become a serious concern when running applications on HPC
systems. Although these systems were designed to mainly run simulation codes as fast as possible,
due to the ever-increasing size of the simulation outputs, the in situ visualization has gained
increasing attention. In situ visualization uses the same HPC system to execute a part or even the
entire visualization processing, and there are currently a variety of tools and libraries that facilitate
domain scientists to integrate them with their simulation codes. Among different approaches,
image- and video-based in situ visualization has been widely adopted as an effective approach for
the subsequent offline visual analysis. In this approach, a large number of renderings are required
at every visualization time step and can consume a considerable computational resource. Fugaku
adopted PowerAPI, which enables the users to set the power mode for their jobs. However,
simulation and visualization codes may have different processing behaviors requiring different
power settings for obtaining the most energy-efficient runnings.
We have investigated the computational cost and energy consumption of some rendering techniques by using the PowerAPI and KVS (Kyoto Visualization System) on the Fugaku. Since the power mode set for the simulation process may not be the best choice for the visualization step, we have focused on evaluating the power modes for the visualization processing. Given Power API’s capability to adjust power settings while a job is in progress in the tightly-coupled visualization, it becomes possible to change the power setting for visualization independently of the simulation. Thus, it may make both processes more energy efficient, as shown in Fig. 1. From the HPC operational side, we should emphasize that opportunities to save energy from the visualization steps should also be taken seriously when adopting in situ visualization.
In this poster, we shed light on the energy efficiency of the visualization portion that was not considered before, and hope that the obtained findings will be useful for potential users looking to run in situ visualization on the Fugaku and other PowerAPI-enabled HPC systems. - 19Symmetry, topology, duality, chirality, and criticality in a spin-1/2 XXZ ladder with a four-spin interaction.
Mateo Fontaine (Keio University)*; Koudai Sugimoto (Keio University); Shunsuke Furukawa (Keio University) -
We study the ground-state phase diagram of a spin- 1/2 XXZ model with a chiralitychirality interaction (CCI) on a two-leg ladder, which is described by the Hamiltonian
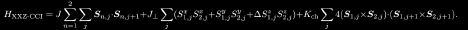
This model offers a minimal setup to study an interplay between spin and chirality degrees of freedom and is closely related to a model with four-spin ring exchange. The spin-chirality duality transformation allows us to relate the regimes of weak and strong CCIs. By applying the Abelian bosonization and the duality, we obtain a rich phase diagram that contains distinct gapped featureless and ordered phases. In particular, Neel and vector chiral orders appear for easy-axis anisotropy, while two distinct symmetry protected topological (SPT) phases appear for easy-plane anisotropy. The two SPT phases can be viewed as twisted variants of the Haldane phase. We perform numerical simulations based on infinite density-matrix renormalization group to confirm the predicted phase structure and critical properties. We further demonstrate that the two SPT phases and a trivial phase are distinguished by topological indices in the presence of certain symmetries. - 20Thicket: Seeing the Performance Experiment Forest for the Individual Run Trees
Stephanie Brink (LLNL); Michael McKinsey (Texas A&M University); David Boehme (LLNL); Connor Scully-Allison (University of Utah); Ian Lumsden (University of Tennessee); Daryl Hawkins (Texa A&M University); Katherine E. Isaacs (University of Utah); Michela Taufer (University of Tennessee); Olga Pearce (LLNL)* -
Thicket is an open-source Python toolkit for Exploratory Data Analysis (EDA) of multirun performance experiments. It enables an understanding of optimal performance configuration
for largescale application codes. Most performance tools focus on a single execution (e.g., single
platform, single measurement tool, single scale). Thicket bridges the gap to convenient analysis in
multidimensional, multi-scale, multi-architecture, and multi-tool performance datasets by
providing an interface for interacting with the performance data.
Thicket has a modular structure composed of three components. The first component is a data structure for multi-dimensional performance data, which is composed automatically on the portable basis of call trees, and accommodates any subset of dimensions present in the dataset. The second is the metadata, enabling distinction and sub-selection of dimensions in performance data. The third is a dimensionality reduction mechanism, enabling analysis such as computing aggregated statistics on a given data dimension. Extensible mechanisms are available for applying analyses (e.g., top-down on Intel CPUs), data science techniques (e.g., K-means clustering from scikit-learn), modeling performance (e.g., Extra-P), and interactive visualization. We demonstrate the power and flexibility of Thicket through two case studies, first with the open-source RAJA Performance Suite on CPU and GPU clusters and another with a large physics simulation run on both a traditional HPC cluster and an AWS Parallel Cluster instance. - 21Enhancing Meteorological Modelling: Integrating Dual Precipitation Radar Data into the NICAM-LETKF System for Improved Forecasting
Michael Goodliff (RIKEN)* - This project focuses on configuring the NICAM-LETKF system with a robust integration of Dual Precipitation Radar (DPR) observations from the Global Precipitation Measurement (GPM) core satellite. It involves the intricate setup and calibration of the Nonhydrostatic ICosahedral Atmospheric Model (NICAM) and Local Ensemble Transform Kalman Filter (LETKF) framework to effectively assimilate and leverage dual precipitation radar data on a 28km grid. This adaptation aims to significantly enhance the model's predictive capabilities by integrating crucial observational inputs. By establishing this refined system, the project aims to advance meteorological modelling techniques, offering improved accuracy and precision in forecasting weather patterns and associated weather phenomena. The poster presentation will outline the system's development, explain its functionality, and clarify future research prospects enabled by this framework.
- 22A rank-mapping optimization tool based on simulated annealing using MPI trace information
Akiyoshi Kuroda (RIKEN R-CCS); Yoshifumi Nakamura (RIKEN R-CCS); Kazuto Ando (RIKEN R-CCS)*; Hitoshi Murai (RIKEN R-CCS); Chisachi Kato (The University of Tokyo) - A rank-mapping optimization tool based on simulated annealing using MPI trace information is proposed. As an application, the fluid simulation software FrontFlow/Blue is targeted. Using an unstructured grid, this application solves the Navier-Stokes equation discretized with a finite element method. When an application of such an unstructured grid is executed in a distributed parallel manner, assigning the MPI process responsible for each subdomain of the entire computational domain to the physical coordinates of each node in the network topology is generally not continuous. As a result, the MPI communication between adjacent subdomains, socalled “adjacent communication,” is performed between physically distant nodes, and the communication performance deteriorates due to communication route congestion. This problem can occur in any directly connected network topology. To attack this problem, we implemented the method for optimizing the mapping of the rank of the MPI process to the physical coordinate of the node in the network topology. Our method is based on the simulated annealing to reduce the value of the evaluation function calculated using MPI communication trace log information. At present, rank mapping optimization has been performed for a maximum of 768 processes, and as a result, a communication time reduction of approximately 25% has been achieved. Although this tool is implemented assuming Fugaku’s network topology, it can be applied to general systems with a directly connected network.
- 23Bias-Exchange Adaptively Biased Molecular Dynamics for Dimerization of Amyloid β Precursor Protein
Shingo Ito (RIKEN CPR)*; Yuji Sugita (RIKEN CPR) - Replica-Exchange Umbrella Sampling (REUS), which is an on-grid exchange algorithm, is a powerful tool to calculate free energy along collective variables (CVs). However, it requires huge computational resources, especially for the free energy calculations on multidimensional CVs. We combined the bias-exchange, which is a non-grid exchange algorithm, with adaptively biased molecular dynamics (ABMD), which is a kind of metadynamics method, to decrease the computational resources while keeping the accuracy of free energy. This new method called Bias-Exchange Adaptively Biased Molecular Dynamics (BE-ABMD), showed good performance for the free energy calculation of dimerization of the amyloid b precursor protein as compared with conventional REUS, and it succeeded in dramatically decreasing the computational cost on 4D-CVs about less than 1% of the cost by REUS with the same accuracy.
- 24A rank-mapping optimization by smoothing network link traffic using information entropy
Akiyoshi Kuroda (RIKEN R-CCS)*; Kazuto Ando (RIKEN R-CCS); Yoshifumi Nakamura (RIKEN R-CCS); Hitoshi Murai (RIKEN R-CCS); Chisachi Kato (The University of Tokyo) - In order to reduce the communication time on the supercomputer Fugaku, we are currently trying to optimize communication time using rank-mapping using a general-purpose flow solver, which is based on Large eddy simulation (LES), FrontFlow/blue (FFB). The main communication in FFB is isend/irecv. The problem with the direct communication network (Tofu network topology) on the Fugaku is that communication conflict as the number of hops outside Tofu unit increases, and it was needed to avoid this problem. We are currently developing a general-purpose rank-mapping optimization annealing tools to reduce the number of hops for rank pairs that have a large amount of communication. At this time, the evaluation function to be annealed can have selected one defined by the number of hops. For more information on this topic, please refer to the other presentation "A rank-mapping optimization tool based on simulated annealing using MPI trace information". Furthermore, we also considered an evaluation function that considers the effective use of network links. To make effective use of network links, it is necessary to prevent communication from being localized to specific links. Rank-mapping space is a finite discrete space, and the number of states can be strictly counted, so it is possible to define and calculate information entropy regarding link usage. In this study, we attempted to maximize the information entropy calculated from the number of states of all link traffic. This annealing calculation made it possible to smooth the link usage rate. However, it is not possible to reduce the number of hops, and the communication flow rate cannot be reduced [Figure.1]. Furthermore, we defined free energy as an evaluation function using its calculated information entropy and attempted annealing using a constant temperature canonical ensemble. We will also report on a comparison with the annealing results using the Metropolis Monte Carlo method [Figure.1] that we have performed so far.
- 25Machine Learning of Observation Operator for Satellite Radiance Data Assimilation in Numerical Weather Prediction
Jianyu Liang (RIKEN R-CCS)*; Takemasa Miyoshi (RIKEN R-CCS); Koji Terasaki (Japan Meteorological Agency) - Data assimilation (DA) in Numerical Weather Prediction is the combination of weather forecast models and observations. It gives an optimal estimate of the initial condition of the model and improves its prediction. For DA, the observation operator (OO) is necessary to derive the model equivalent of the observations from the model variables. It is usually based on the physical relationships between the model variables and the observed variable, so that we call it physically based OO (P-OO). For satellite DA, the radiative transfer models such as RTTOV are used as POO for assimilating brightness temperature (BT) observations from satellites. However, gaining a comprehensive understanding of physical relationships could be time-consuming. Therefore, relying exclusively on P-OO could potentially constrain our capacity to utilize the abundance of new data as early as possible. Since machine learning (ML) is good at finding the complex relationships between variables given enough data, in this study, we propose an innovative method of using ML to build OO without knowing the physical relationships, which we call ML-OO. Our DA system contains the non-hydrostatic icosahedral atmospheric model (NICAM) and the local ensemble transform Kalman filter (LETKF). We used this system to assimilate 1-month conventional observations. Subsequently, the model forecasts after each analysis and BT from the Advanced Microwave Sounding Unit-A (AMSU-A) onboard different satellites were used to train ML models to obtain ML-OO. We tested its performance in the same month in another year. We first assimilated the conventional observations (experiment CONV). We then assimilated additional BT from AMSU-A using RTTOV as OO with online bias correction (experiment CONV-AMSUA-RTTOV). Finally, we assimilated the same observations as experiment CONVAMSUA-RTTOV using ML as OO and without online bias correction (experiment CONVAMSUA-ML). Using ECMWF Reanalysis v5 (ERA5) as the ground truth to calculate the RMSD of the temperature for different experiments, it showed that experiment CONV-AMSUA-ML is slightly worse than experiment CONV-AMSUA-RTTOV but substantially better than experiment CONV, which demonstrates that the ML-OO is effective. The training did not rely on any physically based OO, and this method is purely data-driven. It has great potential for other types of observations so that new observations can be assimilated as soon as possible.
- 26Deformable Systolic Array Platform on 2-D Meshed Virtual FPGA Planes
Tomohiro Ueno (RIKEN R-CCS)*; Emanuele Del Sozzo (RIKEN R-CCS); Kentaro Sano (RIKEN R-CCS) -
Reconfigurable devices, such as FPGAs, are expected to become the accelerators of
choice in HPC systems because of their flexibility and power efficiency. On the other hand, due
to limitations such as memory and network bandwidth and the amount of resources on the chip,
some effort will be required to deliver the high performance demanded by HPC applications. A
tightly coupled FPGA cluster, in which a dedicated network connects a large number of FPGA
devices, has been proposed as an answer to these requirements. Similar to traditional parallel
systems, FPGA clusters are oriented to achieve high performance through the cooperative
operation of each device. However, they face problems such as the need to develop an efficient
communication system among FPGAs, the lack of memory bandwidth, etc.
To improve the usability of such FPGA clusters, VCSN, which establishes virtual network connections between arbitrary FPGAs, has been proposed. We have built a VCSNbased system that integrates and operates virtually 2-D meshconnected FPGAs, which is not feasible in direct connections. We consider these virtual 2-D mesh-connected FPGAs as a huge computational plane on which we propose stream processing using highly efficient dedicated circuits. We propose a systolic array platform with arbitrarily customizable size and shape as a demonstration.
Our proposed deformable systolic array platform utilizes multiple FPGAs connected by a virtual network topology constructed by VCSN. Since the Intel PAC D5005 FPGA board used in this study has two network ports, only a one dimensional topology can be constructed by direct connections with common cables. However, the virtual link functionality provided by VCSN allows us to virtually construct a two dimensional mesh topology and form the virtual FPGA plane shown in Figure 1. Virtual links can be easily reconfigured, allowing the FPGA plane of the appropriate size and shape to be reconfigured in a fraction of the time required by the application.
As shown in Figure 1, this system provides scaleable memory bandwidth by simultaneous read/write to/from offchip memory on each FPGA board. Each FPGA board is installed on a CPU server, and the CPU drives a DMA controller on the FPGA to move data between the memory and the systolic array. We employ the MPI library to drive the DMA controllers on all the FPGAs to simultaneously operate the entire systolic array on multiple FPGAs. We implemented a simple wavefront systolic array with data queuing at each DPU for performance evaluation. The DPUs perform multiply and accumulate (MAC) operation when the input data from the two directions are aligned.
The performance evaluation with systolic arrays of various sizes and shapes, shown in Table I, showed that the operational performance increases in proportion to the number of FPGAs, although the overall performance is limited by the network bandwidth. In the future, we will evaluate the performance using real-world applications and improve the performance by implementing higher compute density. - 27A Control Simulation Experiment for Severe Rainfall Event in Hiroshima in August 2014
Yasumitsu Maejima (RIKEN R-CCS)*; Takemasa Miyoshi (RIKEN R-CCS) -
Abstract: To predict severe weather, convection resolving numerical weather prediction (NWP)
is effective. This study explores a Control Simulation Experiment (CSE) aimed at controlling
precipitation amount and locations to potentially prevent catastrophic disasters by simulating
different scenarios of interventions of small perturbations taking advantage of the chaotic nature
of severe weather dynamics. In this study, we perform a CSE using a regional NWP model
SCALE-RM for a severe rainfall event which caused catastrophic landslides and 77 fatalities in
Hiroshima, Japan on August 19 and 20, 2014.
We perform a 1-km-mesh, hourly-update, 50-member observing system simulation experiment (OSSE) for this rainfall event initialized at 0000 UTC August 18. This provides the initial conditions for a 6-hour ensemble forecast at 1500 UTC August 19. To create small perturbations to change the nature run, we take the differences of all model variables between an ensemble member having the heaviest rain and another ensemble member having the weakest rain. We normalize the perturbations so that the maximum wind speed is 0.1 m s-1. In this preliminary CSE, we try to control the heavy rainfall by giving the perturbations to the nature run in the OSSE at each time step from 1500 UTC to 1600 UTC on August 19, although the perturbations for all variables at all grid points are something beyond human’s engineering capability. In the nature run, 6-hour accumulated rainfall amount from 1500 UTC to 2100 UTC reaches 210 mm at peak. By contrast, the rainfall amount decreases to 118 mm in the CSE. We plan to apply limitations to the perturbations. - 28Performance Evaluation of Multi-Precision Conjugate Gradient Method in CPU/GPU Environment Using SYCL
Takuya Ina (Japan Atomic Energy Agency)*; Yasuhiro Idomura (Japan Atomic Energy Agency); Toshiyuki Imamura (RIKEN R-CCS) -
State-of-the-art supercomputers are based on CPUs/GPUs with a wide variety of
architectures, including Nvidia, AMD, and Intel. Each manufacturer provides its own
programming environment for its architecture: Nvidia provides CUDA, AMD provides HIP, and
Intel provides DPC++. Therefore, it is necessary to develop a code using different programming
environments for each supercomputer.
In addition, low-precision floating-point number arithmetic performance has become several times higher than double-precision floating-point number arithmetic performance due to the high computing needs for machine learning, and low-precision floating-point number arithmetic performance is becoming more important. However, each architecture has a different hardwaresupport for floating-point number types. Therefore, there is a problem that when unsupported floating-number types are used, the calculation cannot be performed or the performance is degraded due to software emulation.
Thus, the recommended programming environment and available floating-point types differ depending on the architecture, making it difficult to develop a common code for multiple architectures. Although it is possible to create architecture-independent codes by using OpenMP and language standards such as C++ stdpar and do concurrent for Fortran, it is difficult to efficiently execute fine grained parallel processing using thousands of threads. In addition, the performance-aware libraries such as Kokkos and RAJA, which abstract parallel processing for easy code portability between architectures, are not available on some architecture. For example, they are not available on Fugaku and FX1000.
DPC++, Intel's preferred programming model, is an implementation of a programming language called SYCL, which is a portable programming language standardized by the Khronos group and based on C++, allowing a single source code to run on multiple CPUs/GPUs. In addition, since there are multiple implementations of SYCL, performance improvement can be expected by selecting an implementation suitable for the architecture and the algorithms used. In addition, since Intel supports DPC++, efforts and information on SYCL will be widely available in the future.
In this study, we evaluated the performance of the multiple-precision conjugate gradient (CG) solver using SYCL, with sparse matrix storage formats of Compressed Row Storage (CRS) and Diagonal Storage (DIA) for the 3-D Poisson equation. We tested the CG solver with half-precision (fp16), single-precision (fp32), and double-precision (fp64).
On the Intel CPU Cascade Lake environment, performance gains of fp16 were respectively 0.69x and 0.47x in CRS and DIA formats compared to fp32 due to the lack of hardware support for fp16. However, fp32 solvers with CRS and DIA formats were respectively 1.78x and 2.03x faster than fp64, and fp64 showed the same level of performance as OpenMP in both CRS and DIA formats. On the FX1000 environment, the performance of the CRS format was almost the same for fp16, fp32, and fp64, and fp64 was 0.85x slower than OpenMP. However, in DIA format, fp16 was 1.45x faster than fp32 and fp32 was 1.75x faster than fp64, showing reasonable performance gains. fp64 was confirmed to have the same performance as OpenMP. On the Nvidia A100 environment, fp16 was 1.38x and 1.44x faster than fp32 in CRS and DIA formats, respectively. fp32 was 1.47x faster than fp64 both in CRS and DIA formats. fp64 was confirmed to have the same performance as CUDA. - 29Acceleration of gREST simulations on Fugaku supercomputer
Jaewoon Jung (R-CCS)*; Chigusa Kobayashi (R-CCS); Yuji Sugita (R-CCS) - Generalized Replica Exchange with Solute Tempering (gREST) is a useful enhanced sampling algorithm for various biological systems. In this scheme, solvent temperatures are the same in all replicas, while solute temperatures are different and are exchanged frequently between replicas to explore various solute structures. We apply the gREST scheme to large biological systems on the Fugaku supercomputer. First, we reduced communication time on a multidimensional torus network by optimally matching each replica to MPI processors. This approach applies not only to gREST but also to other multi-copy algorithms. Second, we performed energy evaluations, necessary for free-energy estimations, on-the-fly during the gREST simulations. Using these two advanced schemes, we observed good scalability results on the Fugaku supercomputer. These schemes, implemented in the latest version of GENESIS software, could open new possibilities to answer unresolved questions on large biomolecular complex systems with slow conformational dynamics.
- 30Mixed Precision solvers for Lattice QCD on supercomputer Fugaku
Issaku Kanamori (RIKEN R-CCS)*; Tatsumi Aoyama (University of Tokyo); Kazuyuki Kanaya (University of Tsukuba); Hideo Matsufuru (KEK/SOKENDAI); Yusuke Namekawa (Hiroshima University); Hidekatsu Nemura (Osaka University); Keigo Nitadori (RIKEN R-CCS) -
Lattice QCD (LQCD) is a physics application to treat interaction of quarks and gluons.
It is one of typical HPC applications on massive parallel system. The most time consuming part of
LQCD simulation is solving discretized partial differential equation called the Dirac equation, for
which iterative solvers like CG are used. To achieve a high performance in solving the Dirac
equation on modern supercomputer systems including supercomputer “Fugaku”, it is important to
utilize low precision floating number operations.
On this poster, we present the performance and convergence property of iterative solvers on Fugaku with a mixed precision scheme. A mixed precision scheme with double and single precisions has been a common technique in LQCD simulations. We also discuss use of the half precision floating point operations. Depending on the parameter of the simulation, especially the value of quark mass, iteration counts needed for convergence drastically change. In the mixed precision scheme, the total iteration counts also depend on the convergence condition of the low precision solver.
The code is implemented with Bridge++ code set which is optimized for Fugaku. - 31Coarse-grained description of structural changes for multi-chain/multi-domain proteins
Chigusa Kobayashi (RIKEN R-CCS)*; Yuji Sugita (RIKEN R-CCS) -
Recent advancements in experimental techniques within structural biology have
enabled the elucidation of structures for large proteins, particularly multi-chain/multi-domain
proteins, under various physiological conditions. As a result, these findings have caused active
research into the relationship between protein structure and biological functions. However,
observing the dynamics of structural changes experimentally remains exceedingly difficult.
Molecular Dynamics (MD) can elucidate protein dynamics and structures at atomic-level resolution. Thanks to recent advancements in computing power, it has become feasible to simulate multi-domain and multi-chain proteins for longer periods of time. This requires the extraction of complex motions from extensive trajectory data. Indeed, various attempts have been made to perform dimensionality reduction on the motion of large proteins, aiming to finding significant movements. Among the approaches for dimensionality reduction, one method involves a coarse graining representation of proteins. In this study, proteins are described as domains and hinge regions between domains. Additionally, an extra point is placed on each domain to represent rotation/twist of the domain. We apply the description to three multi-domain or multi-chain proteins and demonstrate that domain motions could be adequately described. - 32Large-scale Molecular Dynamics Simulations of TDP-43 and Hero11 Protein Condensates
Cheng Tan (RIKEN R-CCS)*; Yuji Sugita (RIKEN R-CCS) - Biomolecular condensates formed through liquid-liquid phase separation play a pivotal role in many critical biological processes. However, the detailed physical interactions and mechanisms driving the formation and regulation of these condensates remain elusive, primarily due to experimental resolution limitations. In this study, we report on our large-scale molecular dynamics (MD) simulations of condensates formed by the protein TDP-43 and its regulatory counterpart, Hero11. Utilizing high-performance computing resources, we have modeled the interactions within these protein condensates. Our methodology integrates both coarse-grained (CG) and all-atom simulations within the GENESIS MD software, thereby providing a thorough perspective of the phase behaviors of proteins. Initially, CG simulations were employed to generate the structure of hundreds of homotypic TDP-43 condensates and heterotypic condensates comprising both TDP-43 and Hero11. Subsequently, these CG structures served as the foundation for reconstructing all atom models of the protein condensates. By resolving structural problems encountered during the CG-to-AA backmapping process, we successfully obtained models free from common issues such as ring penetration and chirality errors. The reconstructed systems, comprising approximately 2.5 million atoms, were then simulated for around 2 microseconds using the supercomputer Fugaku. Our analysis focused on the protein secondary structure propensity and the distributions of protein atoms, water molecules, and ions within these systems. Our findings offer a deeper understanding of the factors affecting the stability and morphology of protein condensates, both external and internal. The large-scale MD simulations employed in this research have proven to be a potent tool in unraveling the intricate mechanisms underlying protein condensation. This study not only furthers our basic knowledge of biomolecular interactions but also holds potential for influencing the development of treatment strategies for diseases associated with protein aggregation.
- 33Efficient Edge-Cloud Computing and Communication Platform
Peng Chen (AIST)*; Yiyu Tan (Iwate University); Du Wu (Tokyo Institute of Technology); Mohamed Wahib (RIKEN R-CCS); Yusuke Tanimura (AIST) - We present an advanced edge-cloud computing and communication platform tailored for the Post-5G era. Our approach involves the creation of a programming model aimed at efficiently optimizing computational bottlenecks across various accelerator architectures, including X86 CPUs, ARM-based CPUs, GPUs, and Field-Programmable Gate Array (FPGA). Additionally, we concentrate on improving communication patterns between the edge and the cloud to address the communication challenges within the edge-cloud computing environment. Moreover, we leverage cutting-edge storage solutions like CSD storage to facilitate data caching within the distributed edge-cloud environment. To minimize data transfer overhead and ensure robust data privacy, we employ lossless data compression algorithms, followed by encryption using state-of-the-art high-security algorithms.
- 34Adaptive Observation Error Inflation with the Assimilation of High-Frequency Satellite Observations under an OSSE Framework with NICAM-LETKF
Rakesh Teja Konduru (RIKEN R-CCS)*; Jianyu Liang (RIKEN R-CCS); Takemasa Miyoshi (RIKEN R-CCS) -
In our research, we explored the complexity of assimilating high-frequency satellite
data into the NICAM-LETKF data assimilation system via an Observing Systems Simulation
Experiment (OSSE). Three distinct experiments assimilated clear-sky AMSU-A satellite
observations at different frequencies: hourly (1H), bi-hourly (2H), three hourly (3H) and every six
hours (6H), alongside conventional observation data. Our findings revealed that 1H and 2H
assimilations resulted in higher Root Mean Square Error (RMSE) for air temperature compared to
3H and 6H assimilation, indicating an introduction of dynamic imbalances at more frequent
assimilation intervals. These imbalances were assessed using the second time derivative of vertical
velocity and were found to be approximately 5% greater in 1H and 2H than in 3H and 6H.
To mitigate the identified imbalances in 1H, we adjusted horizontal localization parameters and inflated observation errors. The adjustment of horizontal localization in IH (HLOC) showed a reduction in air temperature RMSE by 5-10% but did not significantly affect the dynamic imbalance. Conversely, inflating observation error standard deviations manually by 60% in the 1H (Rinfl) experiment diminished imbalances by 5-10% and enhanced the global and tropical representation of air temperature, decreasing RMSE by 10-15%.
Despite these improvements, the manual tuning required for observation error standard deviations proved computationally intensive. To streamline this process, we applied the Adaptive Observation Error Inflation (AOEI) method that adjusts observation error standard deviations online by considering innovations. AOEI not only reduced the imbalance and RMSE effectively in the 1H experiment (AOEI) but also demonstrated superior performance compared to the 3H and 6H assimilation and comparable results to the 1H (Rinfl). This approach was consistent in the 2H (AOEI) experiment as well. Consequently, our study concludes that the AOEI method can successfully rectify the imbalances triggered by high-frequency assimilation in the NICAMLETKF framework. - 35Development of a discriminative model to determine the structural accuracy of an antibody-antigen mutant models based on geometrical interaction descriptors
Shuntaro Chiba (RIKEN R-CCS)*; Yasushi Okuno (Kyoto University); Mitsunori Ikeguchi (Yokohama City University); Masateru Ohta (RIKEN R-CCS) - The suitability of an antibody for development as a pharmaceutical product is determined based on its properties such as activity and stability, which must thus be thoroughly evaluated prior to use as a therapeutic or diagnostic agent. Regarding activity, amino acid mutations are performedfrom thelead antibodyto obtain antibodies with increased binding affinity. To narrow downpromising candidates from thelarge number of possible mutants it is necessary to predict the affinity changes based on themodelstructures of the antigen-antibody mutant complex. To accurately and confidently predict changes in affinity, mutant model structures must be valid and reliable.However, even when considering a single mutant model structure, many mutant model structures are generated because both the amino acid side chain conformation and the arrangement of water molecules around the mutatedamino acidsare highly diverse.Therefore, it is not easy to determine which of these many model structures is valid and reliable. The purpose of this research is to develop a prediction method to determine whether a model structure of an antigen-antibody complex is valid or not, that is, whether the model structure iscrystal structure-like or not.Machine learning model was built using interaction descriptors which are derived from interactions such as hydrogen bond and so-called weak interactions(CH-Ointeraction, CH-πinteraction, etc.)between the mutated amino acids and the surroundingsincluding waters. The high-performance computing resources were used to generate the data for training and test and to train the model.This research has made it possible to automatically and quickly verify the structure of mutation models of antigen-antibody complexes, and has demonstrated the usefulness of prediction methods using interaction descriptors, including weak interactions.
- 36Properties of gapless systems represented by tensor network ansatz
Wei-Lin Tu (Keio University)* - In simulating the modern quantum many-body systems many physicists have paid lots of attention to the application of tensor network (TN) ansatz, which is known to be very accurate for gapped systems due to the obedience of area law. However, gapless states, which are known for hosting abundant physics and phenomena, can hardly be as well dealt by TN with finite bond dimension (D). Still, some remnant effects for the ground state can be witnessed by using the TN ansatz. In the first part of my presentation I will talk about our recent results studying the Heisenberg ferromagnet with cubic anisotropy. While a more accurate phase diagram is provided, the emergent phenomenon on the critical phase boundary can also be captured with a finite-D simulation from the infinite projected entangled-pair state. Next, I will show that by using the generating function approach for tensor network diagrammatic summation, previously proposed in the context of matrix product states, the effective excited state ansatz can be efficiently constructed for evaluating some further properties in two dimensions. Our benchmark results for the spin-1/2 transverse field Ising model and Heisenberg model on the square lattice provide a desirable accuracy, showing good agreement with known results. We envision that the further application of our methodology can be used to gain more understanding for the peculiar states, such as the gapless spin liquid phase.
- 37Using machine learning to find exact analytic solutions to analytically posed physics problems
Sahel Ashhab (National Institute of Information and Communications Technology)* - We investigate the use of machine learning for solving analytic problems in theoretical physics. In particular, symbolic regression is making rapid progress in recent years as a tool to fit data using functions whose overall form is not known in advance. Assuming that we have a mathematical problem that is posed analytically, e.g. through equations, but allows easy numerical evaluation of the solution for any given set of input variable values, one can generate data numerically and then use symbolic regression to identify the closed-form function that describes the data, assuming that such a function exists. In addition to providing a concise way to represent the solution of the problem, such an obtained function can play a key role in providing insight and allow us to find an intuitive explanation for the studied phenomenon. We use a state-of-the-art symbolic regression package to demonstrate how an exact solution can be found and make an attempt at solving an unsolved physics problem. We use the Landau-Zener problem and a few of its generalizations as examples to motivate our approach and illustrate how the calculations become increasingly complicated with increasing problem difficulty. Our results highlight the capabilities and limitations of the presently available symbolic regression packages, and they point to possible modifications of these packages to make them better suited for the purpose of finding exact solutions as opposed to good approximations. Our results also demonstrate the potential for machine learning to tackle analytically posed problems in theoretical physics.
- 38Optimizing Matrix Multiplication on Arm Architectures
Du Wu (Tokyo Institute of Technology )*; Peng Chen (AIST); Toshio Endo (Tokyo Institute of Technology, AIST); Satoshi Matsuoka (RIKEN R-CCS); Mohamed Wahib (RIKEN R-CCS) - We presents armGEMM, a novel approach aimed at enhancing the performance of irregular General Matrix Multiplication (GEMM) operations on popular Arm architectures. Designed to support a wide range of Arm processors, from edge devices to high-performance CPUs. armGEMM optimizes GEMM by intelligently combining fragments of auto-generated micro-kernels, incorporating hand-written optimizations to improve computational efficiency. We optimize the kernel pipeline by tuning the register reuse and the data load/store overlapping. In addition, we use a dynamic tiling scheme to generate balanced tile shapes, based on the shapes of the matrices. We build armGEMM on top of the TVM framework where our dynamic tiling scheme prunes the search space for TVM to identify the optimal combination of parameters for code optimization. Evaluations on five different classes of Arm chips demonstrate the advantages of armGEMM. In most cases involving irregular matrices, armGEMM outperforms state-of-theart implementations like LIBXSMM, LibShalom, OpenBLAS, and Eigen.
- 39Efficient Co-Design of Hardware and Algorithms for SLT-based Graph Neural Networks
Jiale Yan (Tokyo Institute of Technology)*; Hiroaki Ito (Tokyo Institute of Technology); Kazushi Kawamura (Tokyo Institute of Technology); Thiem V Chu (Tokyo Institute of Technology); Daichi Fujiki (Tokyo Institute of Technology); Masato Motomura (Tokyo Institute of Technology) -
Graph Neural Networks (GNNs) are widely used in diverse graph-related tasks,
including recommendation systems, drug discovery, energy physics, and more. These networks
handle complex tasks at multiple levels, such as nodes, edges, and graphs. However, the intricate
structure of these graphs makes GNN computations both communication- and computationintensive. While research has focused on specific types of GNNs, like Graph Convolutional Neural
Networks for node-level tasks, there is a growing gap between the development of advanced GNNs
and the capabilities of hardware accelerators. This gap underscores the critical need for highperformance computing (HPC) solutions that can keep pace with the evolving demands of GNNs,
highlighting their essential role in supporting the next generation of graph processing, particularly
in the cloud.
Our study tackles the challenges depicted in Figure 1, by utilizing a novel approach that integrates hardware and algorithm co-design as shown in Figure 2. It leverages the Strong Lottery Ticket (SLT) mechanism for GNNs and develops an efficient hardware architecture to support it: 1. For the algorithm side, the hardware-aware SLT-GNN exploration utilizes SLT in GNN and provides model candidates for acceleration. The SLT demonstrates the existence of highperforming subnetworks within a randomly initialized model by pruning a GNN without any weight training. As illustrated in Figure 3, this process employs multi-supermasks, and the weight is pruned after randomly initiating. Our methodology extends to a wide range of Graph Neural Networks, from shallow to deep architectures, such as Graph Convolution Network (GCN), Graph Attention Network (GAT), Graph Isomorphism Network (GIN), and deepGCNs. It incorporates adaptive thresholds to enhance performance during partial training phases. Through extensive evaluation of diverse datasets, including open graph benchmarks (OGB), the optimized SLTGNNs show accuracy comparable to dense-weight learning models while achieving significant memory savings (up to 98.7% reduction) as shown in Figure 4. 2. For the hardware side, thanks to SLT-GNN exploration, all random weights are generated on the fly with a weight generation unit, which does not need off-chip memory access. Based on this mechanism, our proposed architecture incorporates multi-level designs, including: (a) Flexible scheduling for the sequence of execution in GNN processing stages, allowing for the prioritization of either aggregation or combination. (b) Efficient handling of product orders, such as row-wise products and outer production, tailored for sparse computations across various GNN layers. The (a) and (b) features’ adaptability considers multiplication operations and limited on-chip memory resource constraints. (c) A dedicated matrix multiplication is designed for edge-embedding tasks in GNNs, which differs from conventional approaches such as relying on simple Sparse-Sparse Multiplication (SpMM) or General MatrixMatrix Multiplication (GEMMs) in node-level tasks. This architecture efficiently supports node, edge, and graph-level tasks with edge embeddings.
In conclusion, this work with SLT-based GNNs presents a triple-win scenario characterized by three key achievements: exceptional sparsity levels (exceeding 90%), competitive performance in terms of accuracy, and superior memory efficiency. This combination effectively contributes to energy-efficient graph processing. - 40Inverse estimation of radiation source distribution from air dose rates: Introduction of Digital Platform 3D-ADRES-Indoor
Susumu Yamada (Japan Atomic Energy Agency)*; Masahiko Machida (Japan Atomic Energy Agency) -
Radioactive materials leaked from reactors resulted in numerous hot spots in the
Fukushima Daiichi Nuclear Power Station (1F) buildings, and have posed obstacles to its
decommissioning of 1F. To solve this problem, Japan Atomic Energy Agency (JAEA) has
conducted research and development of digital techniques for inverse estimation of radiation
source distributions and countermeasures against estimated sources in virtual space for two years
from 2021 based on the subsidy program "Project of Decommissioning and Contaminated Water
Management" performed by the funds from the Ministry of Economy, Trade and Industry.
Moreover, the renewal project has started in April 2023.
In these projects, we have developed the platform software “3D-ADRES-Indoor” to enable general users to estimate easily the source distributions from the observed air dose rates using LASSO (Least Absolute Shrinkage and Selection Operator) regression. It has been reported that the inverse estimation can be properly executed using the conventional LASSO in 3D building models constructed with uniform cells. However, since the shape of an actual reactor building is complicated, its structure cannot be represented using uniform cells. When we apply the conventional LASSO regression to such a model, we find that the inverse estimation accuracy significantly decreases. Therefore, we have proposed the evaluation function of the LASSO that considers non-uniform cells, and we succeeded in properly estimating the source distribution.
In this presentation, we will discuss the efficiency of our proposed LASSO scheme for the models with non-uniform cells. Furthermore, we will introduce the function of the Digital Platform “3D-ADRES-Indoor”, which incorporates inverse estimation for the source distribution from air dose rates using our proposed scheme. - 41General and Scalable Framework for GCN Training on CPU-powered Supercomputers
Chen Zhuang (Tokyo Institute of Technology)*; Peng Chen (AIST); Xin Liu (AIST); Toshio Endo (Tokyo Institute of Technology); Mohamed Wahib (RIKEN R-CCS) -
Graph Convolutional Networks (GCNs) have become indispensable tools across
various domains, yet their application to large-scale graphs in distributed full-batch training
scenarios presents significant challenges. The inefficiency arising from irregular memory access
patterns and the substantial communication overhead hampers the scalability of GCNs on CPUpowered supercomputers. In response to these challenges, this paper introduces novel and versatile
aggregation operators tailored to address irregular memory access patterns efficiently.
Our proposed solution extends beyond aggregation operators, incorporating a pre-postaggregation approach and leveraging an integer quantization method. These enhancements collectively contribute to a substantial reduction in communication costs during the distributed training of GCNs on large-scale graphs. The resulting framework is not only general and efficient but also scalable, providing a comprehensive solution for overcoming the limitations imposed by memory access patterns and communication overhead.
With the combination of these techniques, we formulate an efficient and scalable distributed GCN training framework. Experimental evaluations conducted on diverse large graph datasets demonstrate the remarkable efficacy of our approach. Our method achieves a notable speedup of up to 6x compared to state-of-the-art implementations, showcasing its ability to scale seamlessly to thousands of high-performance computing (HPC)-grade CPUs.
Furthermore, our framework maintains a delicate balance between computational efficiency and model fidelity. We ensure that the scalability improvements do not come at the expense of model convergence and accuracy. Remarkably, our approach positions CPU-powered supercomputers on par with GPU-powered counterparts in terms of performance. This achievement is particularly noteworthy given the substantially lower cost and power budget associated with CPU-based architectures. - 42The nature of the chemical bonds of high-valent transition-metal oxo and peroxo compounds.
Takashi Kawakami (Osaka University)*; Koichi Miyagawa (University of Tsukuba); Mizuki Otsuka (Osaka Univercity); Mitsuo Shoji (Univercity of Tsukuba); Shusuke Yamanaka (Osaka Univercity); Mitsutaka Okumura (Osaka Univercity); Takahito Nakajima (RIKEN); Kizashi Yamaguchi (Osaka Univercity) - In this presentation we investigate the nature of the chemical bonds of the high-valent transition metal oxo (M=O) and peroxo (M-O-O) compounds in chemistry and biology. The basic concepts and theoretical backgrounds of the broken-symmetry (BS) method are revisited to explain orbital symmetry conservation and orbital symmetry breaking for the theoretical characterization of four different mechanisms of chemical reactions. Beyond BS methods using the natural orbitals (UNO) of the BS solutions, such as UNO CI (CC), are also revisited for the elucidation of the scope and applicability of the BS methods. Several chemical indices have been derived as the conceptual bridges between the BS and beyond BS methods. The BS molecular orbital models have been employed to explain the metal oxyl-radical character of the M=O and M-O-O bonds, which respond to their radical reactivity. The isolobal and isospin analogy between carbonyl oxide R2C-O-O and metal peroxide LFe-O-O has been applied to understand and explain the chameleonic chemical reactivity of these compounds. The isolobal and isospin analogy among Fe=O, O=O, and O have also provided the triplet atomic oxygen (3O) model for non-heme Fe(IV)=O species with strong radical reactivity. The chameleonic reactivity of the compounds I (Cpd I) and II (Cpd II) is also explained by this analogy. The early proposals obtained by these theoretical models have been examined based on recent computational results by hybrid DFT (UHDFT), DLPNO CCSD(T0), CASPT2, and UNO CI (CC) methods and quantum computing (QC).
- 43Memory-efficient Methods for Graph Transformer Using Strong Lottery Tickets Hypothesis
Hiroaki Ito (Tokyo Institute of Technology)*; Jiale Yan (Tokyo Institute of Technology); Kazushi Kawamura (Tokyo Institute of Technology); Thiem V Chu (Tokyo Institute of Technology); Daichi Fujiki (Tokyo Institute of Technology); Masato Motomura (Tokyo Institute of Technology) -
Graph Neural Networks (GNNs) are models designed to process graph-structured data
in many areas such as recommendation systems, molecular structure analysis, and cybersecurity.
Advanced scientific research and real-time data analysis using GNNs particularly underscore their
importance in high-performance computing (HPC) and cloud infrastructures. With the evolution
of GNNs as shown in Figure 1, the introduction of Graph Transformers, featuring a self-attention
mechanism, has been a significant advancement, especially marked by improved accuracy. Graph
Transformers come at a cost, particularly in memory usage and computational requirements,
especially when handling large-scale data with deep-layer networks. For instance, a standard GCN
model with 3 layers and 64 hidden dimensions might require about 0.236MB of memory, whereas
a GraphGPS model, a type of Graph Transformer with 10 layers and 386 hidden dimensions,
requires approximately 74.1MB, indicating a 105A~ increase in memory usage. The significant
increase in memory usage makes expanding these networks to handle more complex data tasks
challenging, especially in computing environments where resources are heavily used.
In this study, we explore the Strong Lottery Tickets Hypothesis (SLTH) to enhance the memory efficiency of graph transformers. SLTH proposes that subnetworks ("winning tickets") exist within a neural network that can match the original network’s performance without training their weights. Our proposed training framework utilizes SLTH, which comprises four parts shown in Figure 2. 1. Targets: We select the model configuration and decide which component should be applied with SLTH. In the practical training phase, we focus on the key components of the graph transformer, such as the Q (query), K (key), and V (value) in the self-attention mechanism, and the weights of the feedforward network and MPNN weight in Figure 2 (a). 2. SLTH policy: To achieve high accuracy, we integrate the Single-supermask(S-Sup) and Multisupermasks (M-Sup) methods, as shown in Figure 2 (b). The S-Sup utilizes one supermask to prune the weight matrix, while the MSup creates multiple supermasks with different thresholds. During training, we start at a low sparsity level for an effective binary mask and gradually increase it, shown in Figure 2 (c). Moreover, we explore the appropriate number of masks, target sparsity, and scheduling to enhance accuracy. 3. Model candidates: We determine the Pareto-optimal models that achieve comparable accuracy with better memory efficiency compared with dense-training models in Figure 2 (e). Additionally, we employ a method called ’Folding’ in Figure 2 (d) to further reduce memory usage. Folding converts multiple stages into a single recursive stage through weight sharing, maintaining accuracy while decreasing the total weight count. 4. Hardware-friendly models: We will further implement these SLT-Graph Transformer models on FPGAs, which reduce memory access and can achieve energy-efficient graph processing, as shown in Figure 2 (f).
Preliminary: Experimental findings confirm optimized models substantially reduce memory usage while maintaining high accuracy. On the CIFAR10 dataset for graph classification, the SSup dramatically decreases memory from 0.430MB to 0.033MB (92.3% reduction) and achieves 72.48% accuracy (baseline model with dense weight learning: 72.29%). Our model using M-Sup exhibits greater efficiency than conventional dense training model in node-level classification, e.g., on the PascalVOC-SP dataset, achieves 89.3% memory usage reduction and an F1 score as a dense training model, from 0.373 to 0.384; additionally, PATTERN dataset, it achieves 92.7% memory usage reduction with an accuracy decline of 1%. In this way, our research reduced memory usage by over 90% while achieving comparable accuracy compared to weight-trained models. Increasing the model’s sparsity significantly reduces memory consumption but impacts accuracy. For example, at 10% sparsity, the model maintains high accuracy (85.67%) with a memory usage of 0.13MB. However, at 99% sparsity, while memory drops to 0.08MB, accuracy decreases to 51.39%, highlighting a tradeoff between memory efficiency and accuracy. We will further explore the opportunity to potentially improve accuracy in high-level sparsity (>90%) and the trade-off between accuracy and memory efficiency.
In summary, this research is the first work to implement SLTH to Graph Transformer models, which marks a step forward for SLTH from conventional GNNs to advanced GNNs. The training framework integers optimized SLTH methods such as S-Sup, M-Sup, sparsity scheduling, and more. It could be a potential solution to achieve high graph neural network computation performance within limited hardware resources. - 44Integrating Artificial Intelligence for Enhanced Coarse-Grained Molecular Dynamics Simulations with a Smoothed Hybrid Potential
Ryo Kanada (RIKEN R-CCS)*; Atsushi Tokuhisa (RIKEN R-CCS); Yusuke Nagasaka (Fujitsu Limited); Shingo Okuno (Fujitsu Limited); Koichiro Amemiya (Fujitsu Limited); Shuntaro Chiba (RIKEN R-CCS); Gert-Jan Bekker (Osaka University); Narutoshi Kamiya (University of Hyogo); Koichiro Kato (Kyushu University); Yasushi Okuno (Kyoto University, RIKEN R-CCS) - In all-atom (AA) molecular dynamics (MD) simulations, reproducing spontaneous structural changes in biomolecules poses a challenge due to the rugged energy profile of the force field, especially within a reasonable calculation time. Coarse-grained (CG) models, typically set to a global minimum around the initial structure, prove unsuitable for exploring the structural dynamics between metastable states far from the initial structure without bias. In this study, we introduce a novel hybrid potential integrating artificial intelligence (AI) and minimal CG components, specifically addressing statistical bond length and excluded volume interactions. This hybrid potential aims to accelerate transition dynamics while preserving the protein's inherent characteristics. The AI potential is trained by energy matching using a diverse structural ensemble sampled via multi canonical (Mc) MD simulation and the corresponding AA force field energy, profile of which is smoothed by energy minimization. Application of this methodology to chignolin and TrpCage demonstrates that the AI potential accurately predicts AA energy, evidenced by a correlation coefficient (R-value) exceeding 0.89 between true and predicted energy. Furthermore, the utilization of CGMD simulations based on the smoothed hybrid potential enhances transition dynamics between various metastable states while maintaining protein properties, surpassing results obtained through conventional CGMD and 1 μs AAMD simulations.
- 45Parallel Implementation of Meta-Sampling Based on Straightforward Hilbert Representation of Isolation Kernel
Iurii Nagornov (The National Institute of Advanced Industrial Science and Technology)* -
A recently introduced machine learning method of approximate Bayesian computation
based on the isolation kernel mean embedding in a Hilbert space showed high efficiency in a
parameter estimation problem for high dimensional data. The feature of this method in the usage
of the straightforward Hilbert representation of isolation kernel (SHRIKe) instead of common
kernel trick. Technically the isolation kernel is implemented through a Voronoi diagram algorithm,
facilitating the explicit transformation of simulation raw data to a Hilbert space corresponding to
the model's parameters.
Two primary hyperparameters play a crucial role in the machine learning process: the number of trees, denoted as t, in the isolation forest algorithm, and the number of Voronoi cells, denoted as j, in the generation of partitionings. The interpretation of SHRIKe involves the intersection of all Voronoi cells corresponding to an observation point (s*) in the Hilbert representation of parameter space.
The meta-sampling (MS) algorithm is formulated to systematically generate novel points within the parameter space and assess their similarity with s* without a model run. The overarching goal of meta-sampling is to discern the optimal parameter within the Hilbert space (μ*) by leveraging a designated similarity metric. MS dynamically generates a pool of parameter points, subsequently mapping them into the Hilbert space, and ultimately gauges their similarities to μ*. By iteratively selecting parameters that are in close proximity to the observation, MS repeats this procedure iteratively until convergence to the optimum is achieved.
We have designed MS as a parallel algorithm to expedite computations, and we have instantiated a sampling scheme based on MS. In accordance with the MS algorithm, the computations are implemented as a shared-memory parallel application (OpenMP), employing the initial Voronoi diagrams of the isolation kernel for each iteration of meta-sampling points within each thread of evaluation. Acceleration rate of parallel implementation was in the range 5-30 depending on many hyperparameters like t, j, number of generated points during MS, and size of dataset. - 46Benchpark: A continuous benchmarking system
Gregory Becker (LLNL)*; Olga Pearce (LLNL); Stephanie Brink (LLNL); Jens Domke (RIKEN R-CCS); Nathan Hanford (LLNL); Riyaz Haque (LLNL); Doug Jacobsen (Google); Heidi Poxon (Amazon); Alec Scott (LLNL); Todd Gamblin (LLNL); -
Benchmarking is integral to our understanding of the performance of High Performance
Computing (HPC) systems. While benchmarking is used all across HPC and particularly in
procurement, current practices in benchmarking are very manual and labor intensive. HPC centers
manually curate workloads to communicate to HPC vendors, for procurement, and to validate the
performance of acquired systems. The manual benchmarking process poses a high barrier to entry,
hampers reproducibility, and leads to a duplication of efforts across the entire HPC ecosystem.
Benchpark is a system for continuous benchmarking. It allows cross-site collaboration on benchmark workload definitions, and leverages recent improvements in HPC automation, including continuous integration, package management, and workflow orchestration, to automate the entire pipeline from defining an HPC workload to running across HPC hardware, both at HPC facilities and cloud HPC providers. We have demonstrated the initial implementation of collaborative continuous benchmarking with an open source continuous benchmarking repository. We believe collaborative continuous benchmarking will overcome the human bottleneck in HPC benchmarking, enabling better evaluation of our systems, a more productive collaboration within the HPC community, and eventually better application of machine capabilities to useful science. - 47Performance Evaluation of Three-dimensional Fast Fourier Transforms by Threedimensional Domain Decomposition
Tomoki Sakano (Kobe University)*; Mitsuo Yokokawa (Kobe University); Toshiyuki Imamura (RIKEN R-CCS); Yoshiki Sakurai (Yokohama National University); Takashi Ishihara (Okayama University) -
The three-dimensional fast Fourier transform (3D-FFT) is widely used in various
science and engineering fields. One is used to transform three dimensional physical fields
computed by direct numerical simulations (DNS) of the Navier-Stokes equations discretized by
finite difference methods into Fourier space in order to elucidate the statistical properties of
turbulent flow fields such as an energy spectrum.
Recently, DNSs of compressible isothermal turbulence have been performed with up to 40963 grid points using finite difference methods parallelized by a two-dimensional domain decomposition (pencil decomposition). However, the Reynolds number attained in these DNSs has not been yet high enough to study the properties of the inertial subrange of turbulence. To obtain high resolution results by the DNSs of compressible turbulence using finite difference methods, a larger number of discretized grid points is required, which increases the computational cost. Therefore, highly parallel supercomputers are essential for large-scale DNSs. When executing large scale simulations efficiently on supercomputers, a computational domain must be decomposed into several subdomains, mapped with their local calculation on computational nodes as parallel tasks. In general, a three-dimensional domain decomposition (cuboid decomposition) has an advantage with respect to parallelism compared to the pencil decomposition.
A DNS code with the cuboid decomposition has newly been developed. In the new code, the box computational domain with side length of 2π discretized into a uniform grid of dimensions N × N × N. This grid points are then decomposed in parallel using a cuboid decomposition over np MPI processes with a multi-dimensional Cartesian layout npx × npx × npx. Hence the numbers of grid points allocated to an MPI process in the cuboid decomposition N/npx × N/npx × N/npx. For calculating efficiently statistical properties of turbulent flows on the multi-process, parallelized 3D-FFT should be executed, in which one-dimensional FFT is applied to each Cartesian coordinate sequentially. In the DNS code we referred to, a pencil 3D-FFT was implemented. However, it is difficult to use the pencil 3D-FFT directly for the new code because the data to be transformed is distributed in the cuboid decomposed space. Thus, a parallel 3D-FFT supporting the cuboid decomposition is required in this code.
The 3D-FFT has been vigorously studied by many researchers and implemented as several numerical libraries. A parallel 3D-FFT library FFTE-C and its batched implementation have been developed to apply to a direct numerical simulation (DNS) of incompressible turbulent flows at Kobe University and RIKEN Center for Computational Science (R-CCS). The library supports a pencil and two types of cuboid decompositions, namely pencil 3D-FFT and cuboid 3D-FFT, respectively. The former includes two all-to-all communications to exchange coordinates that are parallelized to apply the 1D-FFT. There are two kinds of 3D-FFT implementations: One includes five all-to-all communications, the other includes three all-to-all communications. We have found that there are difficulties in applying these 3D-FFTs to the DNS code. First, the 3D-FFTs have a -N/2 Fourier mode that is not necessary, because the DNS code handles real values such that density and velocities and is cut in the code. Second, the final Fourier coefficients are not ordered as we expected to use in the DNS code, because the 3D-FFTs by cuboid decomposition are lack of one all-to-all communication to achieve the final data order. These 3D-FFTs are modified so as to use for the DNS code. Moreover, the FFTE-C provides a batched 3D-FFT that can transform multiple three-dimensional data by processing in a pipelined fashion.
In this presentation, we have evaluated performance of the 3D-FFT implementations on the supercomputer “Flow” installed at Nagoya University. Firstly, we measured time of the cuboid 3D-FFT by changing MPI process layouts as the total number of MPI processes is 256 in the condition that N is 1024. When the MPI process layout is 16 × 4 × 4, by specifying the threedimensional torus option in a batch job script, the computation time of the cuboid 3D-FFT is 1.74 times faster than that by not specifying. Compared to the pencil 3D-FFT, the execution time of the cuboid 3D-FFT is longer in most cases.
Secondly, we check weak scalability of the cuboid 3D-FFT. When the number of grid points per process is 1283 , the execution time at the size of (2N)3 is approximately 1.9 times faster than that at the size of N3.
Lastly we also compared the batched 3D-FFT with the no batched one. In the case that the number of grid points is 10243 , the MPI process layout is 8 × 8 × 8, and the torus option is used, the batched 3D-FFT of cube decomposition reduces 18.8% of the execution time in transforming three variables of u, v, and w, compared to the 3D-FFT that transforms three variables sequentially. - 48Visual data exploration for large-scale ensemble simulation data using self-supervised deep metric learning
Sena Kobayashi (Kobe University)*; Naohisa Sakamoto (Kobe University); Yasumitsu Maejima (RIKEN R-CCS); Jorji Nonaka (RIKEN R-CCS) -
In recent years, torrential rains that threaten social life and sometimes human lives have
frequently occurred around the world, and many people have become aware of the threat.
Numerical predictions of such extreme weather events have been actively promoted not only in
meteorology but also as part of HPC research, but the spatiotemporal scale of a localized torrential
rain is usually small and short, thus making difficult deterministic forecasting. Ensemble data
assimilation has become the key to overcoming this problem by combining actual observation data
from state-of-the-art sensor technology with ensemble forecasts that predict weather phenomena
by using probability. Such HPC-based ensemble simulations produce large, time-varying,
multivariate, and multi-valued outputs that are particularly challenging to visualize and analyze.
In such simulations, in addition to the traditional task of examining spatiotemporal behavior among
ensemble members, understanding how ensemble members change over time becomes highly
important.
In order to make the probability predictions more precise, it is necessary to use a large number of ensembles, and there are growing expectations for visualization techniques that can efficiently and effectively analyze these sets of ensemble data. As confirmed in the study by Wang et al., various visualization and visual analysis methods have already been proposed so far for such data. This can also be confirmed in an extensive survey on meteorological data analysis done by Rautenhaus et al., where the visual analysis of ensemble data appears as an important topic. Although various ensemble data visualization and visual analytics methods and approaches exist, it is still challenging to analyze multiple members, variables, and time steps simultaneously by a single approach. Usually, there is a necessity to limit the target of the analysis, such as by fixing one of the variables or time steps, and after combining different visualization methods, it becomes possible to obtain an overview or make necessary comparisons.
However, it becomes difficult to have an overview or to visually analyze the time evolution of a member of interest as the number of ensemble members increases due to the proportionately increase in the data size. Fofonov et al. proposed a visualization method to overview the time evolution of ensemble members based on their similarity. However, since it is still not easy to search for regions that show characteristic changes, an exploratory visual analysis method that not only gives an overview but also provides information that can provide clues for limiting the area for the analysis is still required.
Therefore, in this work, we proposed a visual analysis system that can search for similar structures and their temporal evolution among the members from the ensemble simulation results. The user interface consists of several linked views to enable an overview as well as a comparative analysis to find members, times, or spatial regions of interest (Figure 1). In addition, we have also developed a search system for similar structures by using self-supervised deep metric learning to make the comparisons more efficient.
A better understanding of the behavior of ensemble members is expected to improve the accuracy of the simulation models thus contributing to the mitigation of extreme weather disasters caused by torrential rains. - 49Detection of early warning signals and the description of state transition of infectious disease outbreak
Megumi Oya (RIKEN, Chiba University)*; Tetsuo Ishikawa (RIKEN, Chiba University, Keio University, The University of Tokyo); Eiryo Kawakami(RIKEN, Chiba University) -
Early warning signals of the state changes during the pandemic of an infectious disease
allow countermeasures to be taken in a good time. However, the epidemic dynamics of infectious
diseases are complicated because various factors, such as social and biological factors, affect each
other and make it challenging to apply the simulation models in a social context. In particular, it
is difficult to predict the rapid convergence of infection. On the other hand, machine learningbased methods require data collection over a certain period, so it’s difficult to train on the spot
during the dynamic changes of the state of a pandemic. The methodology of advanced predictive
detection as an early warning signal before the state changes are required only using the simple
data readily available. As an example of COVID-19, we are developing a method to detect and
describe the state changes of the COVID-19 pandemic.
The daily number of COVID-19 infected cases by age group is widely collected at various units (e.g., national and municipal governments, companies, and other social groups). The dataset used in this study is the daily number of infected cases from England and the US (England for 877 days, US for 765 days) by age group of 10-year increments. We tried two methods to detect the early warning signals of infection spread and convergence during COVID-19 when the infection state changes rapidly as waves depending on social and viral factors. The first one is the LNE (landscape network entropy) method. This method is an application of the dynamic network biomarker (DNB), which is known to detect pre-state transitions. The second one is the PE (Permutation Entropy) method. This is a method for quantifying the randomness of time series numbers used to predict the state changes based on the frequency of the pattern of the sorted number order.
Based on these methods, we also tried to describe the state changes of the pandemic visually. We applied the daily number of infected people to an energy landscape analysis, binarizing the daily cases by increase or decrease compared to one week ago. Energy landscape analysis is a method that shows the frequency of different states in the dataset on a topographical map and can describe state changes as if a ball were moving on a topographical map. From the approach of PE method, we could also obtain statistical complexity that can be plotted in 2 dimensions. The pandemic's daily states can be shown on the topological map of energy landscape analysis and on a 2-dimensional diagram of statistical complexity.
It was found that there were changes in LNE and PE values when there were significant changes in the number of infected people. On the other hand, many noise-like signals were also detected, making distinguishing between meaningful and less meaningfulsignals difficult. On the other hand, a comparison of the landscape method and the number of infected people showed that their position on the topographic map changed depending on the waves. The number of infected cases was also widely distributed on the 2-dimensional plot of statistical complexity, suggesting a relationship between each pandemic state and its position on the 2-dimensional plot.
It is considered that there are two types of timing: timing, where an early warning signal can be detected with some degree of accuracy, and timing, where it is difficult to predict. By developing a method of applying statistical complexity, we would first like to be able to distinguish between timing that is easy to predict and timing that is difficult to predict. In addition, even though an early warning signal aims to capture the precursor phase of change, there are no clear true values for the precursors of pandemic spread and convergence, making it currently difficult to evaluate the accuracy of the signal. It will be necessary to develop evaluation indicators. Combining the energy landscape analysis method with the statistical complexity plotting and permutation entropy will deepen the meaning of the predicted early warning signals and give people advanced notice to take some effective countermeasures. - 50Generative AI for molecule generation in drug discovery using open patent data
Yugo Shimizu (RIKEN R-CCS)*; Masateru Ohta (RIKEN R-CCS); Shoichi Ishida (Yokohama City University); Kei Terayama (Yokohama City University); Masanori Osawa (Keio University); Teruki Honma (RIKEN); Kazuyoshi Ikeda (RIKEN R-CCS) - With the development of compound structure generation methods using generative AI (structure generation AI), it has become possible to mechanically generate compounds with structures that could be drug candidates. However, the structure of a compound generated by structure generation AI may not be suitable as a drug, and even if it is, it may have a known structure(i.e., patented).From an intellectual perspective, confirming the patent status of newly developed compounds is essential, particularly for pharmaceutical companies, but it is difficult to confirm this for each compound generated in large quantities (e.g., one million compounds). In order to quickly determine whether or not a large number of compounds generated by structure generation AI are included in drug-related patents, we constructed a compound database (drugpatent DB) of world drug-related patents based on information extracted from public databases (SureChEMBLand Google Patents Public Datasets), and developed a compound comparison method using InChIKey and SQL. We developed a compound exact match search method using InChIKey and a high-speed matching method using SQLite indexing. Furthermore, we created a structure generation AI model using the compounds in the drug-patent DB as a training set, and performed structure generation to generate patented compound-like structures. In addition, by incorporating the developed compound exact match search method as a reward for the structure generation AI, we controlled the ratio of patented compounds in the structure generation and confirmed that novel molecules with high drug-likeness could be generated. The generation using generative AI with patent information would help efficiently propose novel compounds in terms of pharmaceutical patents.
- 51A Hybrid Factorization Algorithm with Mixed Precision Arithmetic for Sparse Matrices
Atsushi Suzuki (RIKEN R-CCS)* -
A linear system with sparse matrix needs to be solved for numerical simulation of partial
differential equations that are discretized by a finite element method or a finite volume method.
The condition number of the coefficient matrix A of the linear system sometimes becomes very
high due to the jump of physical parameter, multiple constraints in a monolithic form of the system,
and/or large variety of the discretization parameter introduced by adaptive mesh refinement. For
the problem of elasticity with composite material, due to different material parameters, the
condition number κ(A) will exceed 109. For the incompressible flow, the condition number will
take 106 because the linear system consists of both kinematic state and divergence free constraint.
Extremely large condition number like 1014 appears in the system for semi-conductor problem
where the diffusion coefficient for hole or electron distribution depends on the electrostatic field
with exponential weight due to modeling of the drift term. For free boundary problem solved by
the level set approach, the condition number is rather moderate around 103 due to adaptive mesh
refinement for locally higher resolution with reasonable number of unknowns in global.
Furthermore, the coefficient matrix could be singular due to setting of the boundary conditions,
which may naturally happen by modelization or by algorithm for parallelization by domain
decomposition methods. Hence, floating point operation at least with double precision are
mandatory for such simulations.
The direct solver based on the LDU-factorization with proper pivoting strategy can solve such sparse matrices with very high condition number. However computational complexity of the factorization algorithm is very high as O(N2.5) with degrees of freedom N for sparse matrix obtained from finite element approximation by P1 or P2 element. This complexity cannot be reduced, but by using lower precision arithmetic, we could expect faster computation with smaller memory footprint. An advantage of fast and memory efficient direct solver is not only for direct solution strategy of the linear system but also for as a preconditioner combined with domain decomposition technique, e.g., additive Schwarz preconditioner and balanced Neumann-Neumann method.
We propose an improved method with mixed precision arithmetic in a hybrid factorization algorithm. The algorithm consists of decomposition of the sparse matrix into a union of moderate and hard parts during factorization procedure with symmetric pivoting strategy. The standard factorization algorithm e.g.,! multifrontal method performs recursive factorization of small submatrices, which could be executed in parallel and generates the Schur complement matrix whose entries consist of the first separator of the nested-dissection ordering for multi-fronts. Our strategy is to replace the generation process of the last Schur complement matrix by an iterative method, in precise, block GCR method, using factorization in lower precision as a preconditioner. For the preconditioning procedure, it is the essential part to perform forward and backward substations for multiple RHS solution in higher precision with factorized matrices in lower precision. Here actual mixed precision arithmetic is necessary without type conversion of RHS data from higher to lower precision during execution of triangular solver realized by TRSM, BLAS level 3, whose coefficients given in lower precision.
This poster will report numerical efficiency of the proposed algorithm and implementation by using mixed precision BLAS with combination of float/double for lower/higher precision and float/Double-float where double precision with 53 bit mantissa is replaced by combination of two floating point numbers with 48 bit mantissa. Float/double mixed precision arithmetic brings two improvements that memory foot print is reduced to around half and computation is around 30% faster. Usage of Double-float would fit to the future super computing architecture, but it is necessary to take care of both 8 bit less mantissa and narrow range of normal value due to smaller exponent, which forces us to modify the code to keep floating point data in normal value and to avoid underflow, which may be critical during iteration of block GCR method, a member of Kyrlov subspace methods. - 52Achieving Scalable Quantum Error Correction with Union-Find on Systolic Arrays by using Multi-Context Processing Elements
Maximilian Heer (RIKEN R-CCS); Jan Wichmann (RIKEN R-CCS)*; Kentaro Sano (RIKEN RCCS); -
The field of quantum computing is rapidly evolving, with ever more qubits becoming
available. At the same time quantum gate fidelities keep increasing. This enables first experiments
with quantum error correction (QEC) using small code distances, i.e., few physical qubits to
encode a single error corrected logical qubit. For fully fault tolerant quantum computers capable
of executing long running quantum circuits significantly larger code distances will have to be
employed. This poses a significant challenge for the classical computation which is required in
every quantum error correction step. In order to achieve the low latency requirements of
superconducting qubits as well as to improve the logical quantum gate throughput, both efficient
QEC algorithms as well as implementations are required.
Recently it has been shown that an efficient implementation of the Union-Find algorithm on a FPGA can actually reduce the average time for a single quantum error correction round with increasing code distance. This shows that the latency requirements for QEC can be handled by FPGA for arbitrary code distances. However, a major challenge remains for executing QEC algorithms for large code distances on FPGA, namely the strongly increasing resource consumption for large code distances. Together with the difficulty of efficiently parallelizing QEC algorithms, this restricts FPGA based error correction to intermediate code distances too short for truly fault tolerant quantum computing.
Here we present a way to reduce hardware resource consumption of QEC algorithms by using a multi-context approach, trading hardware resources for execution time. The technique we are presenting is developed with our own approach to the Union-Find algorithm in mind, but is sufficiently general to be used with all algorithms which work on decoder graphs with limited connectivity.
Our Union-Find approach represents the decoder graph as a systolic array, with each processing element representing a single ancilla qubit measurement. However, the decoder graph of large code distances would require a systolic array which cannot fit on toa single FPGA. Instead, we propose to create a smaller systolic array constructed from multi-context processing elements. This systolic array only holds a part of the decoder graph. The rest of the decoder graph is kept in memory local to each processing element. Once the systolic array has executed a single step of the Union-Find algorithm, the states of all processing elements are saved in memory and the next part of the decoder graph gets loaded, effectively moving the systolic array over the decoder graph. This gets repeated until the first step of the Union-Find algorithm has been executed on the entire decoder graph, see Figure 1 for a graphical representation. Next, the systolic array loads a previously processed part and executes the next step of the Union-Find algorithm. The entire process is repeated until the full Union-Find algorithm has been executed for the entire decoder graph. To make the implementation as efficient as possible, every processing element is assigned its own BRAM cell. In order to correctly treat the boundary conditions between different parts with the least possible overhead, the movement of the systolic array is not done by translation, but instead by mirroring along the boundaries of the systolic array. Using our approach to split the decoder graph into eight pieces allows for treatinga QEC problem with double the code distance. An interesting feature of our approach is thateven though splitting the problem intonpiecesmeans that our algorithm will take ntimes as long, but part of thatlonger time will be recovered by the faster average decoding time of larger code distances. Also,it is worth noting that our approach does not change the underlying logic of the QEC algorithm, producing identical resultsas if we could fit the entire problem on a single FPGA and thus preserving the algorithm's property such as error probability threshold. - 53Wave Separation in Tsunamis Following the 2022 Tonga Volcanic Eruption: Insights from Air Pressure-Induced Phenomena near Japan
Tung-Cheng Ho (RIKEN R-CCS)*; Nobuhito Mori (Kyoto University); Masumi Yamada(Kyoto University) -
The Hunga Tonga-Hunga Ha'apai volcano erupted at UTC 04:14 on January 15, 2022.
Following the eruption, global tsunami monitoring systems and tide gauges observed tsunami
signals that preceded expected tsunami waves (Carvajal et al., 2022). Recorded data revealed a
fast-traveling velocity of approximately 300-315 m/s (Kubota et al., 2022; Yamada et al., 2022),
significantly faster than the conventional tsunami average velocity of around 200 m/s.
The eruption generated an air pressure pulse known as the Lamb wave (Matoza et al., 2022). Sea surface disturbances induced by the Lamb wave, hereafter referred to as pressure-forced waves, were observed at the same high velocity. These pressure-forced waves were observed much earlier and are considered the fast-traveling tsunamis (Kubota et al., 2022). Studies indicated that pressure-forced waves could generate ocean gravity waves following significant water depth changes, such as those occurring at continental slopes. The generation of ocean gravity waves was first instrumentally recorded after the eruption of the Krakatau volcano in 1883 when air pressure pulses caused major changes in depth (Garrett, 1970).
After the eruption of Hunga Tonga, pressure-forced waves were widely observed for the first time by ocean bottom pressure gauges (OBPGs). Tanioka et al. (2022) reported separated waves observed by OBPGs near the Japan Trench. Their synthetic tests indicated that the separation effect is sensitive to the wavelength of the Lamb wave. Yamada et al. (2022) highlighted that, in comparison to OBPGs, sea surface disturbances were much delayed at tide gauges because the tsunami separated and traveled as an ocean gravity wave after passing the continental slope.
To comprehend the mechanism of wave separation, we conducted two-dimensional simulations using synthetic tests and real bathymetry with the Hunga Tonga volcanic eruption. Our simulations demonstrated that the separated waves consisted of the pressure-forced wave and the ocean gravity wave. The former traveling at the same velocity as the Lamb wave, and the latter was generated at changes in depth. Variations in water depth rescaled the amplitude of the pressure-forced wave, and the amplitude change generated an ocean gravity wave as a result of the conservation of mass. The generated ocean gravity wave traveled at a long wave velocity, which is slower than the Lamb wave and leads to wave separation. The high quality OBPGs S-net stations recorded different stages of the separated waveforms between Japanese east coast and the Japan Trench.
We reproduced the separation of waveforms. Our results suggest that any volcano may induce fast-traveling tsunamis, i.e., pressure-forced waves and ocean gravity waves, as volcanic eruptions excite significant air pressure pulses, such as the 2022 Hunga Tonga or the 1883 Krakatau. Our synthetic tests showed that the pressure-forced wave would be amplified as it travels to deeper waterand reduced in shallow-water areas. The wave heights of ocean gravity waves are associated with changes in depth, implying that a larger depth change results in a larger amplitude change of the pressure-forced wave, and the generated ocean gravity wave is larger. Thissuggests that the induced tsunami wave height is limited when the air pressure pulse travels only in shallow water. Future research on tsunamis in the Atlantic Ocean, such as the Caribbean Sea and the Mediterranean Sea, can improve our understanding of tsunamis induced by air pressure traveling from land. - 55Enhancing Large Scale Brain Simulation with Optimized Parallel Algorithms on Fugaku Supercomputer
Tianxiang Lyu (Juntendo University)*; Zhe Sun (Juntendo University); Ryutaro Himeno (Juntendo University) -
The quest to understand the brain has progressed from experimental and theoretical
phases to the burgeoning field of simulation neuroscience. Driven by big data generated at multiple
levels of brain organization, simulation neuroscience seems to be the only methodology for
systematically investigation on multi-scale brain and the interactions within and across all these
levels. However, simulating the whole human brain is one of the most ambitious scientific
challenges in the 21st century, impeded by issues of scale and complexity. Current spiking neural
networks based brain simulator, like the NEST simulator and MONET, face several operational
challenges on high-performance computing systems, including low computing intensity, high
memory consumption and so on. Addressing these challenges, we introduce an innovative
framework optimized for the Fugaku computing system, demonstrating enhanced performance
compared to the NEST simulator. In our research we constructed a unified framework on Fugaku
Supercomputer, facilitating the generation of neural connections and parallel simulations of brain
models. This framework aims to overcome the limitations imposed by the sparsity of such
scientific problems and aspires to scale up to full-nodes-run on Fugaku. 1. A customized multithreading parallel scheme without mutex or atomic operation when computing pre-synaptic
neurons and post-synaptic neurons interaction, which is the main hotspot of the whole workflow,
maximizing CPU ALU pipeline utilization. 2. An advanced memory scheme, tailored for sparse
synaptic connections, enables unified memory access, optimizing both performance and problem
size capacity. 3. A load balance strategy was introduced to the system from multi-section division
with sampling method in FDPS. The performance is measured using the average time spent on the
benchmark test, a multi-area models of cortical sheet. The comparison between our framework
and NEST includes elapsed time and memory consumption, which exhibits the general
performance on multi-scaling problem size. All variables for numerical computing are both in
double precision of floating-point number without any compression on accuracy.
Despite introducing greater computational and memory complexities, a key point we wish to highlight is the impact of these innovations on scaling simulation performance and capacity. By maintaining numerical integrity, we overcome the limitations imposed by sparsity. This approach significantly advances our ability to support simulations of the entire human brain, marking a substantial improvement over previous methodologies. Our successful application of this framework on the Fugaku Supercomputer demonstrates its potential to handle increasingly larger problems, moving us closer to the ambitious goal of full human brain simulation, a pinnacle challenge in our field. - 56Thermal control of the streamwise vortices in a turbulent square-duct flow by a reinforcement learning
Takashi Mitani (Okayama university); Atsushi Sekimoto (Okayama University)* -
Turbulence in a duct with corners produces the mean secondary flow towards the
corners, which is Prandtl’s second kind. Although the secondary flow is as weak as a few percent
of the magnitude of the mainstream, it has significant effects on heat and mass transport. Uhlmann
et al.(2007) performed direct numerical simulations (DNSs) of incompressible fluid motion
through a straight square duct at the marginal Reynolds number, at which the diameter of the finest
coherent vortical structure is relevant to the duct width, H, and showed that the mean secondary
flow appears to be a four-vortex pattern with vortex pairs on the top and bottom walls (Type I), or
the one with left- and right-side walls (Type II) for a short-time average. The drastic modification
of the secondary flow pattern is considered to be a short time visit to the three dimensional
invariant solution in Navier-Stokes equation in a square duct flow at low-Reynolds numbers,
which exhibits lower skin friction than usual turbulence, and yet higher heat transfer rate than that
of laminar flow.
In general, the control of the complex flow phenomena is hardly achieved because of the nonlinear chaotic property; however, in this study, we would aim for such invariant solutions as a control target, at least at low-Reynolds numbers. An indicator function for the four-vortex invariant is introduced to distinguish between the four-vortex patterns. The four-vortex indicator takes values ranging from -1 to 1, with a positive value of I when the secondary flow is the four vortex pattern with vortices on the top and bottom walls (Type I) and a negative value of I with vortices on the left- and right-side walls.
We introduce uniform heating from the bottom as a control strategy, as in Sekimoto et al. (2011). It has been shown that, in well-developed turbulence in a square duct heated from below, the secondary flow pattern changes significantly due to the interaction between thermal convection driven by buoyancy and the coherent structures driven by turbulence. At the marginal Reynolds number (ReH = 2000-3000; based on the duct width, H, and the mean bulk velocity, ub), the marginal turbulence is somewhat controlled by a constant uniform heating from the bottom wall. The nondimensional control parameter is Richardson number (Ri), the ratio of buoyancy force to inertia, is tested at 0.002, 0.011, 0.02, and 0.2. The secondary flow remains in the usual eight vortex pattern until approximately Ri = 0.011, and then one of the four-vortex patterns of Type II is stabilized at Ri = 0.02. A low-velocity streak appears frequently around the bisector of the side walls, and the four-vortex pattern seems relatively stable with slight temporal variation. Since the natural thermal convection pattern could dominate at a further higher Ri = 0.2 due to gravity, the stabilized four-vortex secondary flow has only been observed within a narrow range of Ri, which requires an advanced control strategy. Also, even at moderate Richardson numbers, it takes a long time (the order of several hundreds of H/ub) to control the secondary flow since it is controlled only by the buoyancy force, which is relevant to turbulence inertia. Therefore, the scaled-up of a well-established nonlinear control strategy with numerical simulation is required.
We use deep reinforcement learning to control the secondary flow autonomously. In the numerical simulations, the Reynolds and Prandtl numbers are fixed at 2400 and 0.7, respectively, and Ri is under control between 0 and 0.1. The agent of reinforcement learning estimates the optimal control policy of Ri from the state vector of the mean and long wavelength modes of the instantaneous cross-sectional velocity components and minimizes the indicator function, I, leading to the four-vortex secondary flow pattern of Type II. The DDPG algorithm is used for the learning algorithm, and ADAM is used for the optimization algorithm. As a result, the secondary flow is successfully maintained as the four-vortex pattern of Type II, and the heating parameter changes at around Ri ≈ 0.02, depending on the flow state. Further development of control strategies, such as spatiotemporal heat sources, and the application, such as efficient heat exchanger or particle separation in a micro-channel, are ongoing. - 57A Camera Focus Point Estimation Approach for Smart In-Situ Visualization
Taisei Matsushima (Kobe University)*; Ken Iwata (Kobe University); Naohisa Sakamoto (Kobe University); Jorji Nonaka (RIKEN R-CCS); Chongke Bi (Tianjin university) - In recent years, with the ever increasing scale and complexity of HPC-based numerical simulations, there has been a growing focus on in-situ visualization to address data I/O issues. However, in-situ visualization has a drawback compared to traditional post-hoc visualization methods in that it reduces the interactivity of the analysis. To address this, many in-situ visualization methods have adopted means of generating a large number of images. However, analyzing the resulting massive images still poses a significant challenge in terms of time and effort. Recently, research has been conducted to automate some aspects of this challenge, aiming for efficient in-situ visualization, that is, for a smart in-situ visualization. For instance, Yamaoka et al. proposed an adaptive time step sampling approach trying to automatically optimize the visualization frequency over time based on the changes in physical quantities of the simulation results. Marsaglia et al. worked to identify user-preferred camera positions, and proposed an approach that uses entropy-based indicators to automatically select the optimal viewpoint position from pre-defined multi-camera setup. Additionally, Iwata et al. proposed a viewpoint trajectory estimation method using information entropy. This method automatically optimizes the camera movement path between selected optimal viewpoint positions for smooth transition between adjacent viewpoints to facilitate posterior analysis. However, these methods still face challenges in identifying distinctive changes within the simulation space due to the use of fixed camera distance from the target object. In this poster, to minimize this problem, we introduce a camera focus point (zoom-level) estimation approach for smart in-situ visualization by using information entropy (Fig. 1). From some initial experiments, we observed that it can generate visualization images, which allow for observing distinctive changes in the simulation results compared to the original images. To implement this approach, we utilized Kyoto Visualization System (KVS), an open-source C++ library, for developing the smart in-situ visualization module to be integrated into the C/C++ or Fortran-based simulation codes. We evaluated using OpenFOAM and handmade CFD simulation codes provided by our domain expert collaborators, and the experiments also included scalability evaluation on the supercomputer Fugaku by using up to 1,024 compute nodes.
- 58Closed BCMP Queueing Network Optimization with Supercomputer Fugaku
Haruka Ohba (Juntendo University)*; Yuki Komiyama (Shizuoka Institute of Science and Technology); Shinya Mizuno (Juntendo University) - Queueing networks are essential in settings like hospitals, banks, and shops. Queueing theory mainly identifies two types: open and closed networks. The BCMP queueing network model, introduced in 1975, is highly versatile within queueing theory. It supports both open and closed networks, accommodates multiple classes, and is compatible with various service mechanisms, making it suitable for diverse societal applications. However, the complexity of closed BCMP queueing networks, especially in calculating normalization constants for large-scale models, has limited their practical application. This research utilizes Fugaku, Japan's advanced supercomputer, to address these challenges. Fugaku's ability to parallelize recursive calculations is crucial, enabling the efficient computation of theoretical values within a closed BCMP queueing network in a practical timeframe. This study includes two primary experiments utilizing Fugaku. The first experiment assesses the time and resources needed to compute theoretical values in a closed BCMP queueing network, using the mean value analysis algorithm. The second experiment focuses on optimizing the number of servers in various facility setups. This optimization considers factors such as the number of locations, their arrangement, and user demographics, all crucial for ensuring smooth service delivery. We calculated the necessary number of servers for each location, employing the mean value analysis method for deriving theoretical values and a genetic algorithm for optimization. The optimization's objective function was based on the standard deviation of the average number of customers, aiming to distribute customers evenly across the network, while adhering to a constraint on the total number of servers.
- 59Unified Programming Environment for Multiple Accelerator Types with Portability
Norihisa Fujita (University of Tsukuba)*; Beau Johnston (Oak Ridge National Laboratory); Ryohei Kobayashi (University of Tsukuba); Keita Teranishi (Oak Ridge National Laboratory); Seyong Lee (Oak Ridge National Laboratory); Taisuke Boku (University of Tsukuba); Jeffrey Vetter (Oak Ridge National Laboratory) -
Ensuring performance portability across a range of accelerator architectures presents a
significant challenge when developing application and programming systems for high
performance computing (HPC) environments. This challenge becomes even more pronounced
within computing nodes that incorporate multiple accelerator types. Each of these accelerators is
distinguished by its specific performance attributes, optimal data layouts, programming interfaces,
and program binaries. Navigating the complexity of multi-accelerator programming has motivated
us to create the CHARM (Cooperative Heterogeneous Acceleration with Reconfigurable
Multidevices) framework, which transparently selects the suitable computations for each
accelerator in a given HPC system.
CHARM-SYCL is a unified programming environment based on the concept for multiple accelerator types to attach the diversity problem in HPC systems. We can use SYCL as the single programming environment and create portable applications that are compatible with many accelerator types in a single executable binary file. The CHARM-SYCL runtime uses the IRIS framework as a backend for accelerators. It is a task-based runtime system developed at ORNL to support multiple accelerator types. IRIS uniformly supports many accelerators and has an internal scheduler to dynamically distribute compute tasks to multiple devices according to the scheduling policy specified by the application.
Unlike other operating systems, Linux has a distribution culture. Under the circumstances, it is difficult for us to run the same binary on different distributions because they have different versions of the Linux kernels, compilers, and libraries. In addition to the differences in the distributions, different systems usually have different configurations because of the differences in the system, such as the type of CPUs or accelerators. This forces users to compile and install the CHARM-SYCL compiler on individual systems to avoid compatibility problems. This process will be a very troublesome task for computer scientists because they are not computer professionals. We want to make the installation process as simple as possible. To solve this problem, we propose the compiler portable mode of the CHARM-SYCL compiler. It is a special configuration mode at compile time of the compiler. It maximizes the compatibility and allows us to run the compiler on the major Linux distributions used in HPC systems with the same binary.
In this poster, we will demonstrate the unification and portability for multiple accelerator types of our proposed system. - 60AWS's Comprehensive Data Analytics Platform
Galla Venkataswamy (Raghu Engineering College (A))*; Raakesh Kumar R (Raghu Engineering College (A)) - Amazon Web Services (AWS) offers a robust and extensive suite of cloud-based services specifically designed to empower organizations of all sizes to effectively extract actionable insights from their data. These services span the entire data analytics lifecycle, from data ingestion and storage to processing, analysis, visualization, and machine learning. Also, AWS provides a comprehensive and powerful platform for data analysis, enabling organizations to unlock the full potential of their data. This abstract also explains the benefits of Data Analysis on AWS.