スパコンはどこまで速くできるのか?

プロセッサ研究チーム チームリーダー
現在のスパコンの計算速度をおもに決めているのはCPU(中央処理装置)とメモリです。
これまでのスパコンは、CPUの性能を上げるともに、多くのCPUを並列で使うことで計算速度を向上させてきました。
しかし、CPUの実体は半導体チップであり、その性能は加工技術や消費電力などの制約を受けるため、性能の向上は頭打ちになりつつあります。
そのような現状を踏まえて、佐野さんはこれまでとは異なるアーキテクチャを研究しています。
コンピュータの速度を上げるために行われてきたこと
現在のコンピュータは、パソコンでも、スパコンでも、CPU(中央処理装置)で計算を行っています。CPUの実体は、「マイクロプロセッサ」と呼ばれる半導体チップで、トランジスタやほかの素子がたくさん集積されています。個々のトランジスタは超小型のスイッチとして働き、スイッチのオンとオフで、2進法の1と0を表します。そして、多数のトランジスタを組み合わせた演算器(計算を行う回路)の中でトランジスタのオン/オフを行うことで、2進数の計算を実現しています。
1971年に、アメリカのインテル社が世界初のマイクロプロセッサを発売して以来、半導体メーカーは、マイクロプロセッサの開発にしのぎを削ってきました。「計算速度を上げるために、1個のマイクロプロセッサの性能をとことんまで上げようとしてきたのです」と、佐野さんは説明します(図1)。
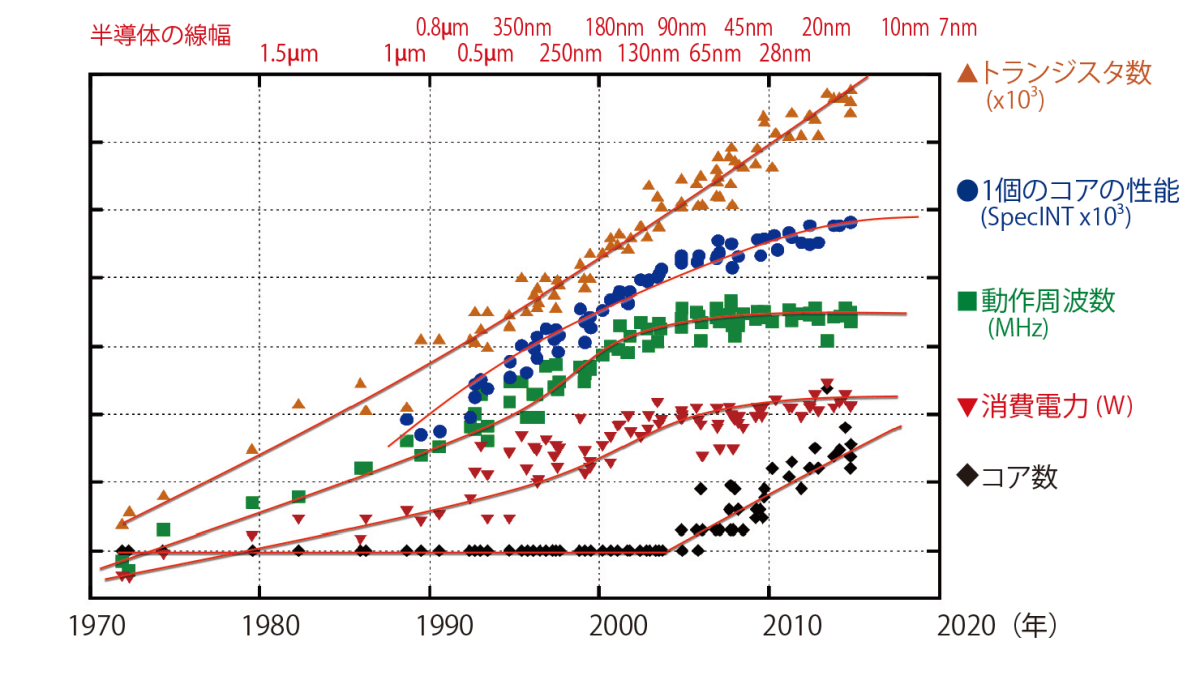
これまで、計算速度を上げるために大きく分けて2つの方法がとられてきました。1つは、チップに集積するトランジスタの数を増やすことです。トランジスタの数を増やせば、1個のマイクロプロセッサでたくさんのデータを処理でき、計算速度は速くなります。実際、マイクロプロセッサの誕生後、半導体の微細加工技術は急速に進歩し、同じ面積により多くのトランジスタを集積できるようになりました。「1つの半導体チップに集積される素子の数は18ヵ月ごとに倍増する」というムーアの法則(法則と呼ばれているが、実際は産業界の開発目標)が、長い間実現されてきたのです(図1のトランジスタ数のグラフ)。
「しかし、トランジスタのオン/オフの切り替えは電力を消費しますから、トランジスタが増えればチップの消費電力も多くなり、発熱も増えます。当然、チップは冷却しますが、それにも限界があるので、チップ全体の消費電力は200W程度以上にはできません。最初のころは、微細化によりトランジスタの動作電圧を下げ、トランジスタ1個の消費電力を下げることができたので、チップに搭載するトランジスタの数を増やしていけたのですが、2005年ごろに、動作電圧を下げると漏れ電流が増えるという問題が出てきて、これ以上の改善は望めなくなってしまいました(図1の消費電力のグラフ)」
計算速度を上げるためのもう1つの方法は、回路の動作周波数を上げることです。マイクロプロセッサの中のトランジスタはばらばらにオン/オフが切り替わるわけではなく、クロックに合わせて一斉に動作します。ですから、その周波数を上げれば、計算速度を上げることができます(図1の動作周波数のグラフ)。しかし、ある程度以上周波数を上げるには動作電圧を高くする必要があるため、やはりチップ全体の消費電力の問題が生じ、2000年代の初めに周波数は頭打ちとなりました。
「そこで開発の戦略は変わり、1つのマイクロプロセッサの性能を極限まで上げるのではなく、効率のよいものをたくさん並べることで計算を速くしようということになりました。こうして登場したのが、『マルチコアプロセッサ』です」。マルチコアプロセッサとは、簡単に言えば、複数のマイクロプロセッサを1つの半導体チップに収めたもので、一つひとつのマイクロプロセッサにあたるものをコアと呼びます。「昨年まで使われていた『京』は、8コアが搭載されたプロセッサを使っていました。今つくられている『富岳』は、52コア搭載のプロセッサを使います。しかし、計算速度をさらに上げるために、コアの数を1000、10000と増やしていけばよいかというと、そうはいかないのです」
これまで以上に計算速度を上げるのが難しいのはなぜか
その背景には、「開発コストの増加」、「半導体の微細加工技術が限界に近づいていて、トランジスタの微細化がなかなか進まない」、「すべてのコアを同時に使うとチップ全体の消費電力が高くなりすぎる」といった技術的な問題があります。しかし、より本質的な問題はコアのアーキテクチャにあると、アーキテクチャの専門家である佐野さんは言います。「アーキテクチャ」という言葉の定義は、使う人や場面によって少しずつ違いますが、佐野さんはこう説明します。「計算機上でアプリケーションを使って問題を解くのは、こういうことをしたいという『要求』です。一方、計算機をつくるのに使われる半導体などのデバイスの特性は決まっていて、それは『制約』となります。この両者をつなぐのが『アーキテクチャ』です。要求を満たすために、制約のあるデバイスを用いてどのような計算機をつくるのかという方式が、アーキテクチャなのです」
現在のほとんどのマイクロプロセッサは、「フォン・ノイマン型」のアーキテクチャ(図2a)を採用しています。「しかし、このアーキテクチャでは、メモリからデータを読み出して計算し、その結果をメモリに書き込んで次の計算のためにまた読み出すというサイクルが必要です。また、計算結果に応じて命令を変えるといった判断のサイクルもあります。これらには回路の遅延が伴うため、計算を速くできないのです」。さらに、「この点を改善する方法もいろいろあるのですが、それを実現する処理回路が必要となるため、計算に使えるトランジスタの数が減り、計算効率は上がらなくなってしまうのです」
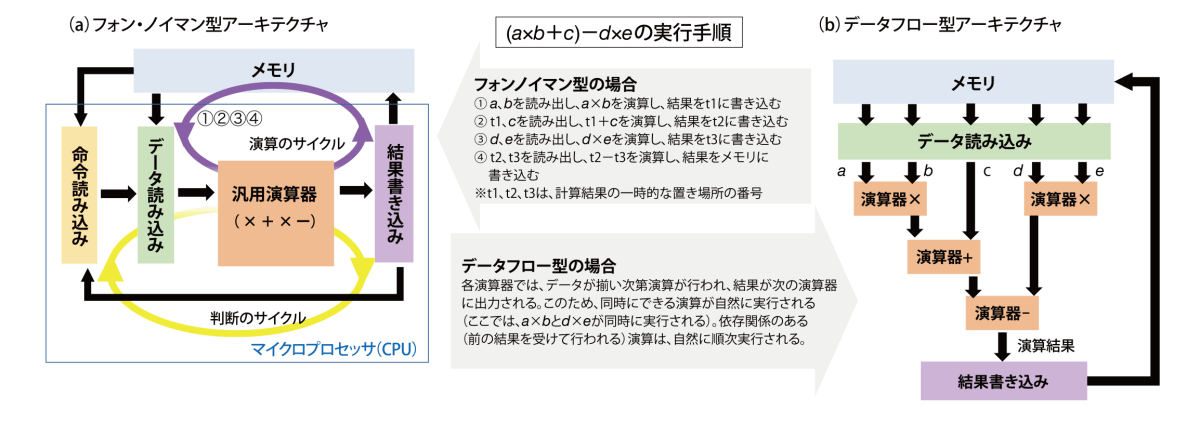
(b)データフロー型アーキテクチャでは、計算式における演算の依存関係の通りに演算器が並んでいるので、毎回命令を読み込む必要はない。 メモリからデータを読み込み、データが揃った演算を次々と行っていくことにより、最後には数式の計算結果が得られ、それをメモリに返す。データを次々に読み込んで計算するパイプラインという方法によって、計算の高速化が可能である。もっと複雑な計算式(例えば、図3や表紙)でも、データフローで計算できる。
マルチコアにした場合、この2つの問題に加え、コア間の通信という問題も起こります。「あるコアで計算した結果を、『キャッシュ』と呼ばれる、チップ上に置かれた一時的なメモリに書き込み、それを必要とするコアに読み込ませる必要があります。キャッシュに置かれたデータをコアが読み書きするには一定の時間がかかるため、コア間のデータの受け渡しや同期の効率が低下してしまい、コアをいくら増やしても、計算を速くできないのです」
データを一方向に流すことで、計算を速くする
これらの問題を解決するために最適なのは、「データフロー」というアーキテクチャだと、佐野さんは考えています。「データフローは1970年代半ばに提案されたもので、計算式の通りに演算器を並べて、そこにデータを流すというやり方です(図2b、図3)。前の計算が全部終わって結果が揃うと自動的に次の計算に進むので、読んで書くというサイクルによる遅延がありません。データが流れていくのに時間はかかりますが、パイプラインという方法を使うと、1つの計算が終わらないうちに次のデータを入れて計算させることができるので、どんどんデータを入れることで、同じ時間でより多くの計算を行えます。これは、読み書きのサイクルのあるフォン・ノイマン型では難しいことです」
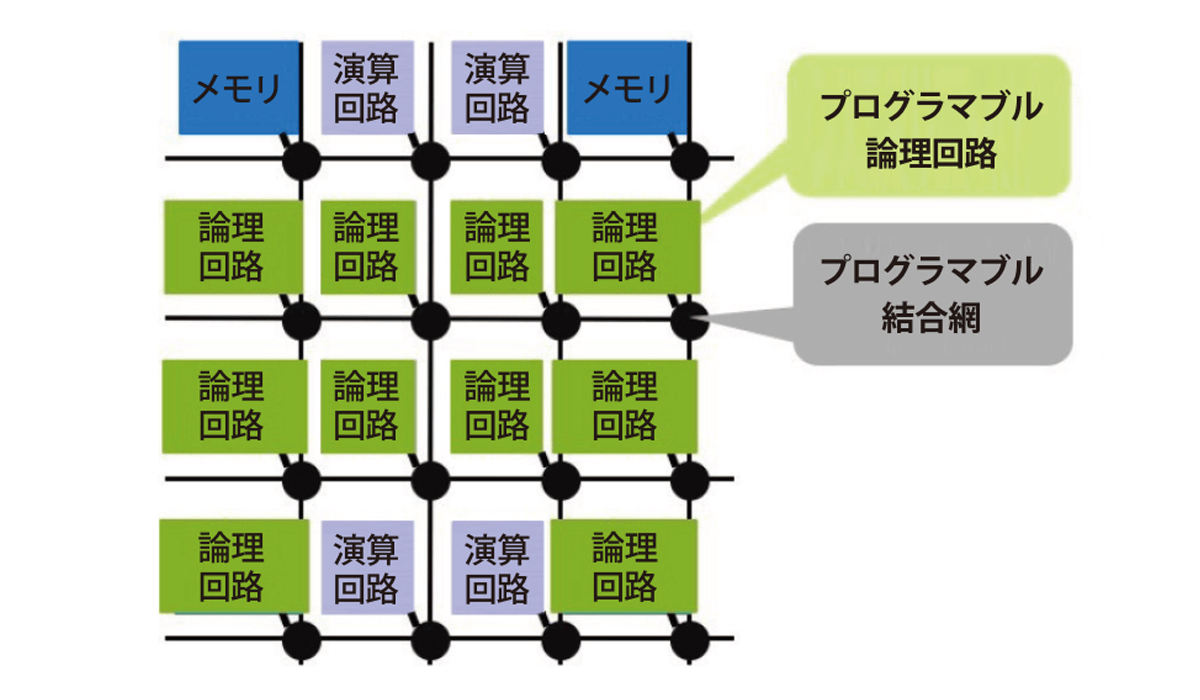
ただし、データフロー型のマイクロプロセッサは、計算式の通りに演算器を並べた回路をもっていなければなりません。そのような半導体チップはどうやってつくるのでしょうか。「FPGA(field-programmable gatearray、図4)という、回路構成をプログラムで変えられる集積回路のチップを使います。最近のFPGAは性能がかなりよくなり、高速計算にも利用できるようになってきました。例えば、FPGAに流体の計算をするデータフロー回路を書き込んで、津波を再現することに成功しました(図5)。計算式通りの回路を使うので、ソフトウェアは不要で、命令を読み込む必要もありません」
(東北大学大学院情報科学研究科 張山昌論教授提供)
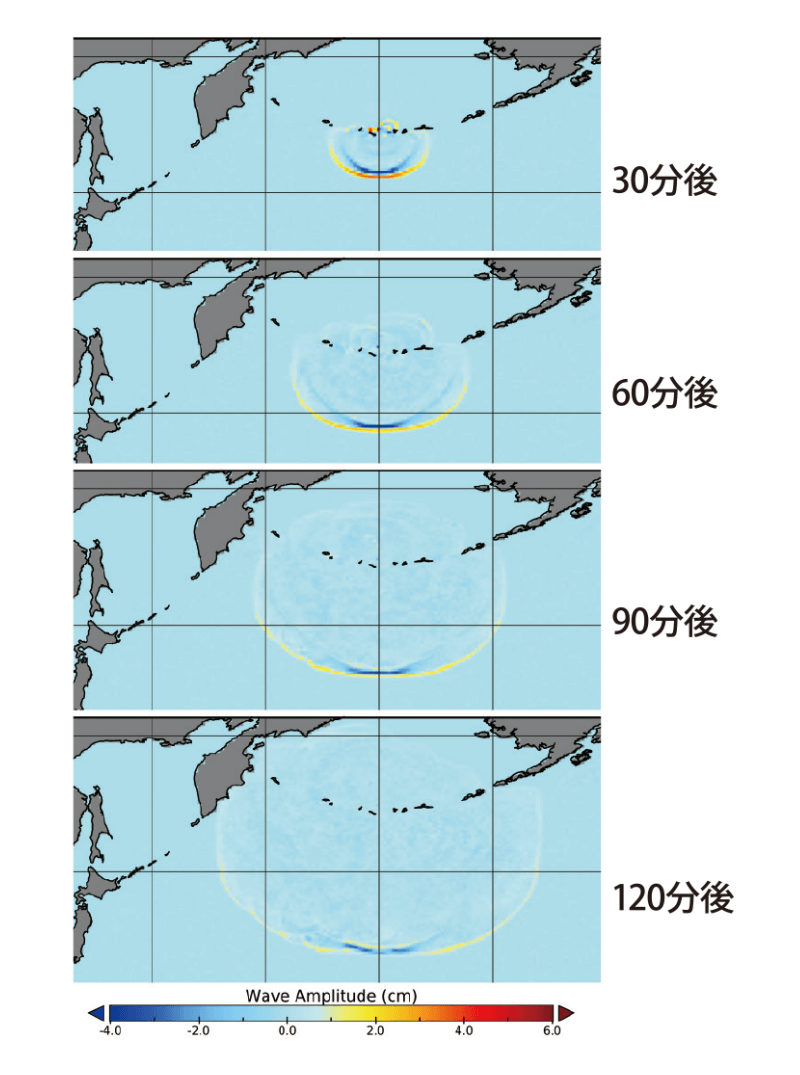
(K.Nagasu et al., Journal of Parallel and Distributed Computing, Vol.106, pp.153-169, DOI: 10.1016/j.jpdc.2016.12.015, 2017.より)
このように、データフロー型マイクロプロセッサを使うと、ある計算に特化した場合に計算を速くできますが、「京」や「富岳」のような汎用型スパコンとは、目指す方向が少し違います。「汎用型スパコンはいろいろな種類の計算を行うことができますが、計算の種類によって実現できる計算性能に幅があります。ですので、汎用型が得意でなく、データフロー型なら速く行える種類の計算に使えたらと考えています。例えば、ゲノムの膨大な塩基配列の比較とか、ディープラーニングの推論などは、データフロー型のほうがずっと速くできると思います」
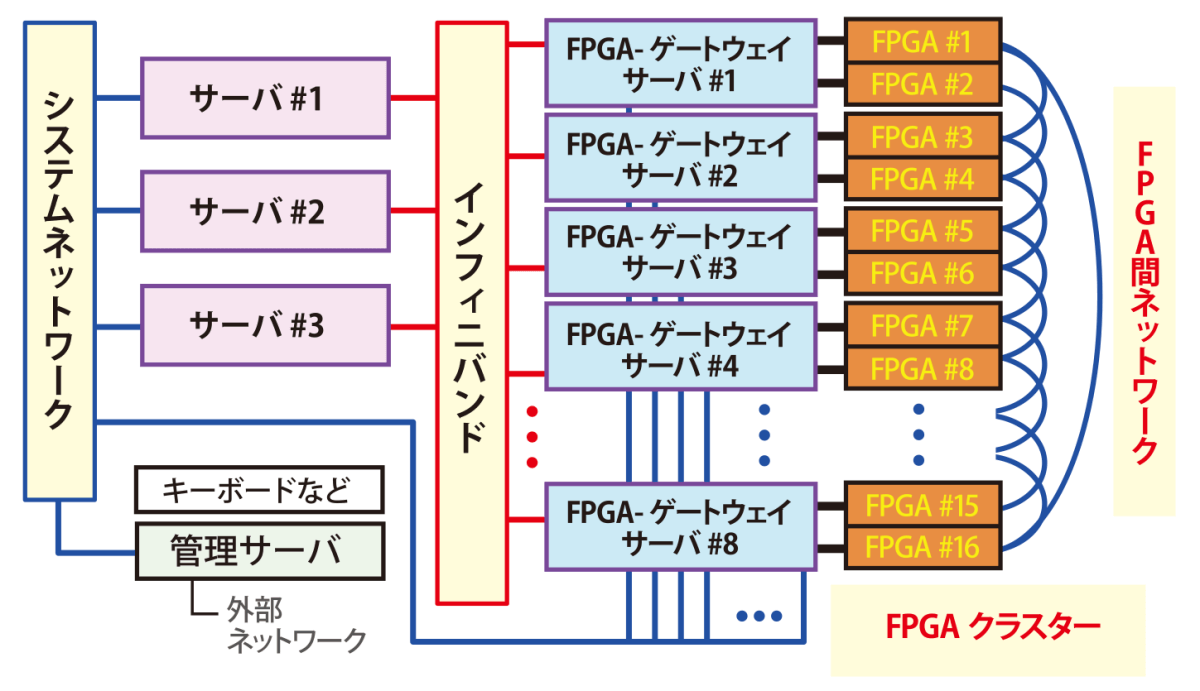
現在、佐野さんは、16個のFPGAとサーバをネットワークでつないだ計算機を試作中です(図6)。「今は、実際に計算をするときの問題点などを検証している段階ですが、FPGAをうまく使って、いくつかの計算に特化した高性能計算機をつくれたらと考えています」
計算をより速くするためには、様々なアプローチがあります。シリコンに替わる新たな半導体材料も開発されていますし、量子コンピュータのように新しい計算原理を使う動きもあります。「しかし、今すぐにできて、効果が大きいのは、特化型の新しいアーキテクチャの開発だと思います」。「富岳」の開発の一方で、新たなアーキテクチャの研究が進む――このような多様性こそが、スパコンを進歩させていく原動力となることでしょう。
(取材・執筆:サイテック・コミュニケーションズ青山聖子)
に収録されています。
