3.1.11.2. 詳細プロファイラ¶
詳細プロファイラは、アプリケーションの指定した区間の実行性能情報の計測および出力を行います。
3.1.11.2.1. 概要¶
詳細プロファイラは、プロファイルデータを計測するfappコマンドと、計測したデータからプロファイル結果を出力するfapppxコマンドの2つから構成されます。詳細プロファイラが計測および出力する情報は以下のとおりです。
時間統計情報
MPI通信コスト情報
CPU性能解析情報
詳細プロファイラの使用の流れは以下のとおりです。
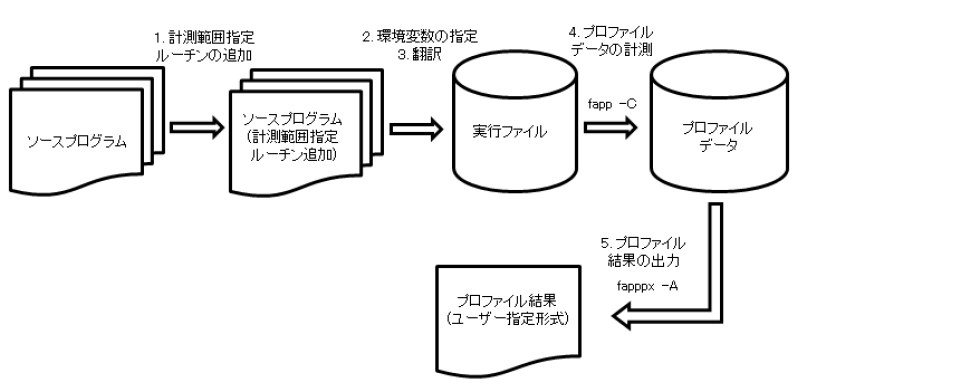
3.1.11.2.2. 計測区間指定ルーチンの追加¶
プロファイルデータを計測する区間の指定に必要な計測区間指定ルーチン/関数をソースコードに追加します。
計測区間指定機能は、Fortran言語のサブルーチン、C/C++の関数として使用可能です。 C/C++の関数を使用する場合は、関数のプロトタイプを宣言するか、または、プロファイラサブルーチンのヘッダファイルをインクルードする必要があります。
言語種別
ヘッダファイル
サブルーチン/関数名
引数
機能
Fortran
なし
(name, number, level)
C/C++
fj_tool/fapp.h
(const char *name, int number, int level)
[引数の詳細]
引数
説明
name
グループ名(基本文字スカラ)。グループ名は、英字、数字、および下線から構成されます。他の文字は使用できません。
number
詳細番号(4バイトの整数型)
level
プライオリティレベル(4バイトの整数型で0以上の整数)
注釈
グループ名と詳細番号を組み合わせ、測定範囲名として区別します。プライオリティレベルが、fappコマンドの
-Lオプションの値より大きい場合は測定を行いません。注意
同じ計測区間名のサブルーチン/関数を複数回呼び出す場合、必ず fapp_start、fapp_stop の順番で呼び出してください。fapp_stop を呼び出す前に再度 fapp_start を呼び出した場合、または、fapp_start を呼び出す前に fapp_stop を呼び出した場合、警告メッセージを出力し、その呼び出しを無視します。
計測区間名が異なる場合、fapp_start、または、fapp_stopが連続しても問題ありません。
fapp_stop を呼び出さずにプロセスが終了した場合、その区間のプロファイルデータは計測しません。
同一の計測区間名に対する計測を複数回実施した場合、全ての計測結果を合算します。
引数 level の値は、fapp_start と fapp_stop で同じ値を指定してください。異なる値を指定した場合、 fappコマンドの
-Lオプションの指定によっては意図しない結果となる可能性があります。引数
nameに "all" かつ、numberに 0 を指定した場合、プログラム全体が対象になります。スレッド情報の計測はマスタースレッドで処理を開始します。マスタースレッド以外のスレッドが呼び出される範囲を計測する場合、マスタースレッドが動作する区間を含めた計測範囲にしてください。
MPIプログラムの場合、計測対象とするすべてのプロセスで同じ計測区間名のサブルーチン/関数を呼び出してください。呼び出しが行われなかったプロセスのプロファイルデータは計測されません。
計測区間指定ルーチンの使用例を示します。
Fortranの例
サンプル指定例
program main ... call fapp_start("foo",1,0) ! 計測区間名"foo1"の計測を開始する do i=1,10000 ... call fapp_start("bar",1,0) ! 計測区間名"bar1"の計測を開始する do j=1,10000 ... end do call fapp_stop("bar",1,0) ! 計測区間名"bar1"の計測を終了する end do call fapp_stop("foo",1,0) ! 計測区間名"foo1"の計測を終了する end program main
すべてのプロセスを計測対象とする例(mpi_initサブルーチンを呼び出す前に計測を開始する)
call fapp_start("foo",1,0) ! 計測を開始する call mpi_init(err) ... call mpi_finalize(err) call fapp_stop("foo",1,0) ! 計測を終了する
すべてのプロセスを計測対象とする例(mpi_initサブルーチンを呼び出した直後に計測を開始する)
call mpi_init(err) call fapp_start("foo",1,0) ! 計測を開始する ... call fapp_stop("foo",1,0) ! 計測を終了する call mpi_finalize(err)
プロセス0のみ計測対象とする例
call mpi_init(err) call mpi_comm_rank(mpi_comm_world,rank,err) if(rank==0) then call fapp_start("foo",1,0) ! プロセス0のみ、計測を開始する end if ... if(rank==0) then call fapp_stop("foo",1,0) ! プロセス0のみ、計測を終了する end if call mpi_finalize(err)
C/C++の例
サンプル指定例
#include "fj_tool/fapp.h" // ヘッダーファイルのインクルード ... int main(void) { int i,j; fapp_start("foo",1,0); // 計測区間名"foo1"の計測を開始する for(i=0;i<10000;i++){ ... fapp_start("bar",1,0); // 計測区間名"bar1"の計測を開始する for(j=0;j<10000;j++){ ... } fapp_stop("bar",1,0); // 計測区間名"bar1"の計測を終了する } return 0; fapp_stop("foo",1,0); // 計測区間名"foo1"の計測を終了する }
すべてのプロセスを計測対象とする例(MPI_Init関数を呼び出す前に計測を開始する)
fapp_start("foo",1,0); // 計測を開始する MPI_Init(&argc, &argv); ... MPI_Finalize(); fapp_stop("foo",1,0); // 計測を終了する
すべてのプロセスを計測対象とする例(MPI_Init関数を呼び出した直後に計測を開始する)
MPI_Init(&argc, &argv); fapp_start("foo",1,0); // 計測を開始する ... fapp_stop("foo",1,0); // 計測を終了する MPI_Finalize();
プロセス0のみ計測対象とする例
MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, &rank); if(rank==0){ fapp_start("foo",1,0); // プロセス0のみ、計測を開始する } ... if(rank==0){ fapp_stop("foo",1,0); // プロセス0のみ、計測を終了する } MPI_Finalize();
3.1.11.2.3. コンパイル/リンク¶
コンパイル/リンク例(MPIプログラムの場合)
[_LNlogin]$ mpifrtpx -Kfast,parallel "ソースファイル名"
コンパイル/リンク例(逐次/スレッド並列プログラムの場合)
[_LNlogin]$ frtpx -Kfast,parallel "ソースファイル名"注意
分割コンパイルを行う場合は、適切なプロファイラのライブラリがリンクされるように、原則としてコンパイル時に指定した最適化オプションは、リンク時にも指定してください。
例)OpenMPを利用するプログラムは、リンク時にも
-Kopenmpオプションを指定する。
3.1.11.2.3.1. Fortranの翻訳時オプションについて¶
オプション
説明
-Nfjprof
ツールライブラリを結合します。 省略時は
-Nfjprofが有効になります。-Nnofjprof
ツールライブラリを結合しません。 プロファイラを使用できません。
3.1.11.2.3.2. C/C++の翻訳時オプションについて¶
モード
オプション
説明
trad
-Nfjprof
ツールライブラリを結合します。 省略時は
-Nfjprofが有効になります。trad
-Nnofjprof
ツールライブラリを結合しません。 プロファイラは使用できません。
clang
-ffj-fjprof
ツールライブラリを結合します。 省略時は
-ffj-fjprofが有効になります。clang
-ffj-no-fjprof
ツールライブラリを結合しません。 プロファイラは使用できません。
3.1.11.2.4. プロファイルデータの計測¶
#!/bin/bash -x
#
#PJM -L "node=8"
#PJM -L "rscgrp=small"
#PJM -L "elapse=01:00:00"
#PJM -x PJM_LLIO_GFSCACHE=/vol000N
#PJM -g groupname
#PJM -s
#
LD="./sample_mpi"
MPIEXEC="mpiexec"
#
fapp -C -d ./tmp -Icpupa,mpi -Hevent=statistics ${MPIEXEC} ${LD}
注意
fappコマンドにより計測したプロファイルデータに対して以下を行った場合、動作保証しません。
プロファイルデータの編集
プロファイルデータの追加、削除、リネーム
3.1.11.2.5. プロファイラのオプション¶
fappコマンドのオプションについて説明します。
オプション
説明
プロファイルデータの計測を指示します。本オプションを省略した場合、エラーメッセージを出力しプログラムの実行を終了します。
profile_dataにはプロファイルデータを格納するディレクトリ名を、相対、または、絶対パスで指定します。指定したディレクトリは新規作成、または、空のディレクトリでなければいけません。実行中にカレントディレクトリを移動するプログラムを解析する場合、profile_dataは絶対パスで指定してください。プロファイラはprofile_dataの下に1000ファイルごとのサブディレクトリを作成します。このため、大規模ジョブが対象の場合もprofile_dataを指定するだけで使用できます。-Hitem
-Inocpupaオプションが指定されていた場合、警告メッセージを出力して本オプションは無効になります。サブオプションevent=event、または、event_raw=event_rawはどちらか1つを必ず指定してください。item:{event=event | event_raw=event_raw } [,method={fast | normal},mode={all | user}]
- event=event
CPU性能解析レポートに使用する情報を計測します。eventには以下のいずれか1つを指定します。
pa1とstatisticsは同値です。{ pa1 | pa2 | pa3 | pa4 | pa5 | pa6 | pa7 | pa8 | pa9 | pa10 | pa11 | pa12 | pa13 | pa14 | pa15 | pa16 | pa17 | statistics}
- event_raw=event_raw
PMUイベント情報のイベント番号を指定して、CPU性能解析情報を計測します。event_raw には、CPUに対応したイベント番号を10進数または16進数表記で指定します。event_raw は、コンマ(,)で区切ることで、最大8個まで指定できます。
- method=fast
CPU性能解析情報の計測方式を指定します。本サブオプションを指定した場合、ハードウェアの情報を直接計測する方式により、高精度のCPU性能解析情報の計測を行います。
- method=normal
CPU性能解析情報の計測方式を指定します。本サブオプションを指定した場合、OSを経由して計測する方法によりCPU性能解析情報の計測を行います。省略時は、
method=normalになります。- mode=all
CPU性能解析情報の計測モードを指定します。本サブオプションを指定した場合、カーネルモードおよびユーザーモードにおける性能計測を行います。
mode=の省略時は、mode=allが有効になります。- mode=user
CPU性能解析情報の計測モードを指定します。本サブオプションを指定した場合、ユーザーモードにおける性能計測を行います。
cpupa|nocpupa} | {cputime|nocputime} | {mpi|nompi}}本オプション省略時の動作は、計測する項目により異なります。CPU動作状況の計測は、-Hオプションが指定されている場合は、-Icpupaが有効になり、-Hオプションが指定されていない場合は、-Inocpupaが有効になります。-I{cputime|nocputime}オプション省略時は、-Icputimeオプションが有効になります。-Icpupaオプションが有効な場合のみ、-Inocputimeが指定できます。MPIコスト情報の計測は、対象がMPIプログラムの場合は、mpiが有効になり、対象が非MPIプログラムの場合は、nompiが有効になります。
- cpupa:
CPU動作状況を計測します。
- nocpupa:
CPU動作状況を計測しません。
- cputime:
ユーザCPU時間およびシステムCPU時間を計測します。
- nocputime:
ユーザCPU時間およびシステムCPU時間を計測しないかわりに、CPU性能解析情報の計測にかかる時間を短縮します。
- mpi:
MPIコスト情報を計測します。
- nompi:
MPIコスト情報を計測しません。
-L level
-L 0が有効になります。exec-file [ exec_option ... ]
プロファイルデータの計測対象となる実行ファイルとオプションを指定します。MPIプログラムの場合、mpiexecから指定します。
3.1.11.2.6. プロファイル結果の出力¶
本操作は使用するノードによって異なるコマンドを使用します。
- ログインノードの場合
fapppxコマンドを使用します。
- 計算ノードの場合
fappコマンドを使用します。
fapppxコマンドの実行例を以下に示します。
[_LNlogin] $ fapppx -A -pall -o tmp.txt -d Fprofd_stati
この例では、全てのプロセスの情報を出力する指定(-pall)をしています。また、プロファイル結果は、デフォルトであるTEXT形式で出力されます。
なお、CPU性能解析レポートの入力用CSVファイルを出力する場合は、-tcsvオプションを指定します。
3.1.11.2.6.1. fapppx/fappコマンドのオプション¶
オプション |
機能・測定値(単位) |
|---|---|
-A
(必須オプション)
|
プロファイル結果の出力処理を指示します。 |
-d profile_data
(必須オプション)
|
プロファイルデータを格納したディレクトリを、 profile_data に相対パスまたは絶対パスで指定します。 |
-Iitem
(ハイフン+大文字アイ)
|
プロファイル結果の出力対象とする項目を指定します。
複数のitemを指定する場合は、カンマで区切ってください。
item:{{
cpupa | nocpupa } | {mpi | nompi}}
|
-o outfile |
プロファイル結果の出力先を指定します。outfile には、出力先ファイル名を相対パスまたは絶対パスで指定するか、または、"stdout"を指定します。
本オプション省略時は、
-ostdoutオプションが有効になります。 |
-pp_no |
プロファイル結果に出力するプロセスを指定します。
p_no には、
N 、input=n 、limit=m、allの中からいずれか1つ以上を指定します。本オプション省略時は、
-pinput=0、limit=16が有効になります。-pオプションにはコンマ(,)を区切りとして、 p_no を複数指定することができます。例えば、
-p3,5,limit=10のような指定ができます。
|
-t{csv | text} |
プロファイル結果の出力形式を指定します。
|
3.1.11.2.6.2. プロファイル結果¶
-Iオプションによって出力を制御できます。プロファイルデータ計測環境情報
時間統計情報
MPI通信コスト情報
CPU性能解析情報