2. TensorFlow 富岳環境¶
2.1. LICENSE条項¶
提供したパッチおよび手順はOSSに提供(Upstream化)しており、Upstream化されたTensorFlow分はApache License2.0ライセンスに準拠します。
2.2. 参考情報¶
TensorFlow-2.11.0 手順書 https://github.com/fujitsu/tensorflow/wiki/TensorFlow-oneDNN-build-manual-for-FUJITSU-Software-Compiler-Package-(TensorFlow-v2.11.0)-JP
TensorFlow-2.7.0 手順書 https://github.com/fujitsu/tensorflow/wiki/TensorFlow-oneDNN-build-manual-for-FUJITSU-Software-Compiler-Package-(TensorFlow-v2.7.0)-JP
TensorFlow-2.2.0 手順書 https://github.com/fujitsu/tensorflow/wiki/TensorFlow-oneDNN-build-manual-for-FUJITSU-Software-Compiler-Package-(TensorFlow-v2.2.0)-JP
2.3. バージョン (checkout.sh、site-packagesなど参照のこと)¶
TensorFlow ver.2.11.0
Horovod ver.0.26.1
oneDNN ver.2.7.0
tensorboard ver.2.11.2
bazel ver.5.3.0
Python ver.3.9.x 以降
numpy ver.1.22.x 以降
scipy ver.1.7.x 以降
h5py ver.3.8.0
batchedBLAS ber.1.0
2.4. 構成¶
最新版のものは、上記GitHubの手順に従いユーザ環境にて構築しご利用下さいませ。 第2ストレージ階層にTensorFlow-2.2.0以前のバージョンについては構築済みのものを公 開しています。サンプル問題は互換ではありませんが、動かし方や性能取得方法など 参考にご利用下さい。
/home/apps/oss/TensorFlow-2.2.0
bin: 実行バイナリ
lib,lib64: ライブラリ
lib/python3.8/site-packages: TensorFlowなどPython module一式
include: インクルードファイル
build: 構築に用いたscript, patch類
example: ResNet-50, OpenNMT, Bert, OpenNMT, Mask R-CNN実行例
docs: ドキュメント類
old: 旧公開バージョン
2.5. 構築方法¶
ご自身で構築される場合は、build以下をご参照下さいませ。手順は、上記参考資料に記載されております。パスなど調整の上ご利用下さいませ。$PATHなどは適時修正が必要です。構築に3時間程度かかります。サンプル実行には、半日ほどかかります。
なお最新版へは順次富岳への組み込みをしておりますが、TensorLow本体内の構造変化に伴い、富岳向け高速化が動作しないことがあります。各バージョンの詳しい制限事項は上記Wikiなど御参照下さい。
$ git clone https://github.com/fujitsu/tensorflow.git
$ cd tensorflow # これ以降このディレクトリを TENSORFLOW_TOP と呼びます
$ git checkout -b r2.11_for_a64fx origin/r2.11_for_a64fx
$ cd fcc_build_script
$ bash 01_python_build.sh
$ ・・・
第2ストレージ階層に配置したバージョンは、Githubで公開されている版をVENVを用いず構築したものです。なるべく絶対パスを埋め込まないように調整しましたので、$HOMEへのコピーやステージングでの使用も可能と想定しています。
2.6. 実行方法¶
本環境一式は、$PATHを通すことでどこに配置しても実行できます。Python moduleはfile数が多いため、多並列では、MDSアクセス高負荷のためimportlibの時間がかかることが想定されます。利用手引き書の、8.2.4.2. 共通ファイル配布のヒントを参考に、必要な共通ファイルをllio_transferで転送するか、tarなどで固めてllio_transferで転送し展開することでステージングによる利用が可能です。
example配下にイメージ読み込み無(Dry Benchmark)のResNet-50の実行例、自然言語処理のOpenNMT、Bert、物体検知のMask R-CNNのサンプルも入っており、高速化ライブラリを読み込めるようになっております。ご参照下さいませ。
手順は、上記参考資料に記載あります。パスなど調整の上ご利用下さいませ。
2.7. 制限事項¶
高速化パッチがあたらなかったり、TensorFlowの仕様変更により、バージョン更新に伴い性能維持が困難でした。
構築問題
bazelが自動で依存関係を見抜けず、自身でbazel設定ファイルを作成する場合は、試行錯誤で設定ファイルの書き直しが必要(100回ほど)です。
富士通コンパイラでC++17 の新仕様「構造化束縛」でコアダンプします。3箇所コード書き替えが必要でした。
動作注意
TensorFlowではバージョン間のAPI変更が大きいため、高速化したサンプルがそのままでは動きません。使用するバージョンに併せて学習コードなどの書き替えが必要です。
fipp/fapp/PAなどにより、HWカウンタ情報が取得できません。 → TensorFlowはpthreadを使用してthread並列をしており、富士通プロファイラの一部の機能は対応していません。
ulimit -h 8092を設定しないとSEGVになるサンプルが増えました.
性能問題
データの持ち方が変更され、TensorFlow-2.11.0では多くのサンプル問題で1/8程度まで性能劣化します。この問題はIntel CPUでも同様です。
2.8. チュートリアル¶
ここでは、富岳でTensorFlowを使用して、画像認識のResnetサンプルを動かす手順を記載します。
富岳にアカウント作成からログインについてはスタートアップガイドを御参考下さい。ここでは、ログイン後に作業領域~/tutorialでの作業を仮定します。
2.8.1. サンプル問題の準備¶
TensorFlowは、/vol0004/apps/oss/TensorFlow-2.2.0があらかじめインストールされてい
ます。その中のexampleを作業場所にコピーします。95_outputに実行
例が入っていますので適時ご参照下さいませ。ここではサイズが大きいので、除外してコピーします。
サンプルはそれ以降のTensorFlowのバージョンと互換ではありません。適時置き換えてご利用下さいませ。
$ cd # $HOMEへ移動
$ mkdir -p tutorial/TensorFlow # 作業ディレクトリの作成
$ cd /vol0004/apps/oss/TensorFlow-2.2.0/example # TensorFlow環境へ移動
$ tar -cf - --exclude=95_output --exclude=95_log . | (cd ~/tutorial/TensorFlow ; tar -xvf -) # 作業ディレクトリへ実行例を除いてコピー
$ cd # $HOMEに戻る
$ cd tutorial/TensorFlow # 作業ディレクトリへ移動
$ ls # 作業ディレクトリの中身を確認
01_resnet 02_OpenNMT 03_Bert 04_Mask-R-CNN env.src env.src.spack
この中に画像認識(Resnet)、自然言語処理(OpenNMT, Bert)、物体検知
(Mask-R-CNN)のサンプルが入っています。またenv.srcには、実行に必要
な環境変数などの設定が入っています。ご自身でTensorFlowを動かす時は、TensorFlowを動
かす前に、$ . env.srcを実行して下さい。
富岳でジョブを実行するためには、pjsub job_name.shと実行します。
job_name.shの先頭にジョブ投入に必要な情報が記載されています。
#!/bin/bash
#PJM -L "rscunit=rscunit_ft01,rscgrp=small" # 384ノードまではsmallを使います
#PJM -L elapse=00:15:00 # ジョブは最大でも15分で終了します
#PJM -L "node=1,freq=2200" # 1ノードを2200MHzで使用します
#PJM --mpi "shape=1,proc=4" # 1ノードをMPI 4プロセスで使用します
#PJM -x PJM_LLIO_GFSCACHE=/vol0004 # TensorFlow本体は/vol0004に置いてあるので指定します
#PJM -j # 標準エラー出力を標準出力にマージします
#PJM -S # ジョブ統計情報の詳細を出力します
また、インタラクティブモードを使って計算ノードに直接ログインすることも可能です。 この場合ジョブ実行はpjsub (job_name).shの代わりに bash (job_name).shとして実行します。
$ pjsub (job_name).sh # バッチジョブでジョブを投入する
$ pjsub --interact -L "node=1" -L "rscunit=rscunit_ft01" -L "rscgrp=int" -L "elapse=1:00:00" --sparam "wait-time=600" -x "PJM_LLIO_GFSCACHE=/vol0004" # 1ノードを1プロセスで1時間使用する
$ pjsub --interact -L "node=1" -L "rscunit=rscunit_ft01" -L "rscgrp=int" -L "elapse=1:00:00" --sparam "wait-time=600" --mpi "proc=4" -x "PJM_LLIO_GFSCACHE=/vol0004" # 1ノードを4プロセスで1時間使用する
$ bash (job_name).sh # インタラクティブでジョブを実行する。
2.8.2. Resnetサンプルの実行¶
ResNet-50のネットワークを用いた画像認識を行なうサンプルコードです。google の公式
モデル(TensorFlow v1.x用) Tag: v2.0 (2019/10/15)を使用します。
ダミーデータを用いており、1ノード学習、データ分散多並列学習、Spackとの併用、LLIOの利用などの
実行、性能取得例を用意しています。
サンプルモデルの設定は必ずしも最速になっているわけではないことに留意してください。
/vol0004/apps/oss/TensorFlow-2.2.0/example/0*/95_outputに富岳での実行結
果の例がありますので比較することができます。
$ cd 01_resnet # 画像認識(ResNet-50)のサンプル問題です
$ ls -1 # ファイルを確認します。以下、順番を入れ替えています
10_setup_resnet.sh # モデル構築 (一瞬)
11_train_resnet-single.sh # 動作確認 (1ノード, 1プロセス、12コア, ダミーデータ) (5分)
12_train_resnet-4process.sh # 動作確認 (1ノード, 4プロセス、12コア/プロセス, ダミーデータ) (5分)
13_train_spack.sh # 一部PythonやPython moduleをSpackにて使用する例
14-0_train_llio_pre.sh # 大並列を想定して、llip_transferで転送するファイルリストを作成する例
14-1_train_llio_main.sh # 作成されたファイルリストからllio_transferを使用して実行する例
15-0_train_llio_spack_pre.sh # 大並列を想定して、llip_transferでSpackを併用しつつ転送するファイルリストを作成する例
15-1_train_llio_spack_main.sh # 作成されたファイルリストからllio_transferを試用して実行する例
16_train_tar.sh # 大並列を想定して、Python moduleをtarで固めて実行する例
17_train_single_prof.sh # TensorBoardによる1ノード性能取得例
18_train_4procs_prof.sh # TensorBoardによる多プロセス性能取得例
19_train_cProf.sh # Python Profiler cProfileによる性能取得例
resnet.patch # 富岳用のpatch
run_all.sh # 全てのサンプルを一括実行するスクリプト
run_llio.sh # llio_transferを用いてファイルリストを作成し、本計算をするスクリプト
run_llio_spack.sh # Spackを使用している時にllio_transferを用いてファイルリストを作成し、本計算をするスクリプト
run_tar.sh # Python関係のファイルをtarで固めて実行するスクリプト
富岳2.2GHzでの1ノードを1プロセスで画像認識の学習する例を実行します。
$ pjsub 10_setup_resnet.sh # 1回実行して、モデルを構築します。
$ pjsub 11_train_resnet-single.sh # 実行 (1プロセス、12コア)
$ less 11_train_resnet-single.sh.(job_id).out # 結果の確認
### Start at Tue Jan 4 02:49:52 JST 2022, .d0011355369
(省略)
INFO:tensorflow:cross_entropy = 7.622652, learning_rate = 0.0, train_accuracy= 0.0
I0104 02:53:20.628397 281473877852704 basic_session_run_hooks.py:262] cross_entropy = 7.622652, learning_rate = 0.0, train_accuracy = 0.0
INFO:tensorflow:loss = 9.018034, step = 0
I0104 02:53:20.634507 281473877852704 basic_session_run_hooks.py:262] loss = 9.018034, step = 0
INFO:tensorflow:global_step/sec: 0.0845045
I0104 02:53:32.462948 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.0845045
INFO:tensorflow:loss = 9.018034, step = 1 (11.831 sec)
I0104 02:53:32.465140 281473877852704 basic_session_run_hooks.py:260] loss = 9.018034, step = 1 (11.831 sec)
INFO:tensorflow:global_step/sec: 0.474424
I0104 02:53:34.567272 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.474424
INFO:tensorflow:loss = 9.012028, step = 2 (2.103 sec)
I0104 02:53:34.568228 281473877852704 basic_session_run_hooks.py:260] loss = 9.012028, step = 2 (2.103 sec)
INFO:tensorflow:global_step/sec: 0.477239
I0104 02:53:36.662617 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.477239
INFO:tensorflow:loss = 8.995026, step = 3 (2.095 sec)
I0104 02:53:36.663505 281473877852704 basic_session_run_hooks.py:260] loss = 8.995026, step = 3 (2.095 sec)
(約100行省略)
INFO:tensorflow:Starting to evaluate.
(約10行省略)
INFO:tensorflow:step = 1 time = 2.978 [sec]
I0104 02:55:03.039637 281473877852704 resnet_run_loop.py:777] step = 1 time = 2.978 [sec]
INFO:tensorflow:step = 2 time = 0.812 [sec]
I0104 02:55:03.852066 281473877852704 resnet_run_loop.py:777] step = 2 time = 0.812 [sec]
INFO:tensorflow:Evaluation [2/25]
I0104 02:55:03.852500 281473877852704 evaluation.py:167] Evaluation [2/25]
INFO:tensorflow:step = 3 time = 0.603 [sec]
I0104 02:55:04.456099 281473877852704 resnet_run_loop.py:777] step = 3 time = 0.603 [sec]
INFO:tensorflow:step = 4 time = 0.542 [sec]
I0104 02:55:04.998743 281473877852704 resnet_run_loop.py:777] step = 4 time = 0.542 [sec]
(省略)
使用できるメモリの範囲でバッチサイズは大きいほど性能の効率は良くなります。但し、
CPUではピークの性能が高くない(単精度で6.6TF程)ため、多くの場合、多ノードでマルチプロセ
スで実行する必要があります。12_train_resnet-4process.shは4プロセスでデータ並
列学習と推論を実行する例です。このスクリプトではTensorFlowを4プロセス起動し、
各TensorFlowが11_train_resnet-single.shと同じ条件の学習・推論を行うので、
全体の処理量は4倍になっています。このため、ひとつのTensorFlowの結果で比べると
11_train_resnet-single.shよりも多少性能が悪くなることに注意してください。
$ pjsub 12_train_resnet-4process.sh # 実行 (4プロセス、16コア/プロセス, Horovod 使用)
$ less 12_train_resnet-4process.sh.(job_id)/0/stderr.1.0 # 結果の確認
(約150行省略)
INFO:tensorflow:cross_entropy = 7.8823295, learning_rate = 0.0, train_accuracy = 0.0
I0104 03:03:40.746693 281473877852704 basic_session_run_hooks.py:262] cross_entropy = 7.8823295, learning_rate = 0.0, train_accuracy = 0.0
INFO:tensorflow:loss = 9.277428, step = 0
I0104 03:03:40.754458 281473877852704 basic_session_run_hooks.py:262] loss = 9.277428, step = 0
INFO:tensorflow:global_step/sec: 0.0645181
I0104 03:03:56.244729 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.0645181
INFO:tensorflow:loss = 9.277428, step = 1 (15.516 sec)
I0104 03:03:56.270637 281473877852704 basic_session_run_hooks.py:260] loss = 9.277428, step = 1 (15.516 sec)
INFO:tensorflow:global_step/sec: 0.345699
I0104 03:03:59.142429 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.345699
INFO:tensorflow:loss = 9.275918, step = 2 (2.875 sec)
I0104 03:03:59.145996 281473877852704 basic_session_run_hooks.py:260] loss = 9.275918, step = 2 (2.875 sec)
INFO:tensorflow:global_step/sec: 0.337184
I0104 03:04:02.116680 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.337184
INFO:tensorflow:loss = 9.271575, step = 3 (2.979 sec)
I0104 03:04:02.124801 281473877852704 basic_session_run_hooks.py:260] loss = 9.271575, step = 3 (2.979 sec)
INFO:tensorflow:global_step/sec: 0.332609
I0104 03:04:05.111564 281473877852704 basic_session_run_hooks.py:702] global_step/sec: 0.332609
(約100行省略)
INFO:tensorflow:Starting to evaluate.
(約10行省略)
INFO:tensorflow:step = 1 time = 4.901 [sec]
I0104 03:05:57.741813 281473877852704 resnet_run_loop.py:777] step = 1 time = 4.901 [sec]
INFO:tensorflow:step = 2 time = 0.988 [sec]
I0104 03:05:58.730467 281473877852704 resnet_run_loop.py:777] step = 2 time = 0.988 [sec]
INFO:tensorflow:Evaluation [2/25]
I0104 03:05:58.730897 281473877852704 evaluation.py:167] Evaluation [2/25]
INFO:tensorflow:step = 3 time = 1.147 [sec]
I0104 03:05:59.878140 281473877852704 resnet_run_loop.py:777] step = 3 time = 1.147 [sec]
INFO:tensorflow:step = 4 time = 1.281 [sec]
I0104 03:06:01.159818 281473877852704 resnet_run_loop.py:777] step = 4 time = 1.281 [sec]
(省略)
2.8.3. LLIO_transferによるPython moduleなどのデータ転送¶
サンプルでは1ノードを用いた例で実行していますが、3rack 1,000並列を越えてくると、画像デー
タの増大やPythonモジュールの読み込みに時間がかかるようになるため、予めデータを第1階
層ストレージに持って行くことをお勧めします。第2階層FEFSへのアクセスを減らすため
16_train_tar.shでは、Python環境一式をtarで固めて、計算ノードで展開
するサンプルスクリプトを用意しています。
しかし、計算ノードでは基本的にtar展開処理に伴うファイルI/Oも遅いため、
llio_transferを用いて、必要なファイルだけ転送する方法を推奨します。
$ rm -Rf strace_log # 不要なファイルを消去します
$ pjsub 14-0_train_llio_pre.sh # 転送すべきファイルをstraceを用いて検索します
$ egrep -v '= \-1 ENOENT|O_DIRECTORY' ./strace_log/strace.0.* | egrep O_RDONLY | cut -d\" -f 2 |egrep ^/vol.... >> llio_transfer.list # 出力されたstraceの結果から、転送するファイルリストを作成します
$ pjsub 14-1_train_llio_main.sh # lliop_transferを用いた本計算です
14-0_train_llio_pre.shで、必要なファイルを取り出すため、ランク0のみstraceを動かして、アクセスしたファイルを出力します。straceの処理は多少時間がかかるため、
batchサイズや繰り返し回数は少なく設定しています。ここで得られたstraceのログから
grepを用いて、転送するファイルリストを作成しています。作成されたファイルリス
トの例です。
$ cat llio_transfer.list # 転送するファイルの確認
/vol0004/apps/oss/TensorFlow-2.2.0/bin/python3
/vol0004/rccs-atd/a01004/TensorFlow/build/TensorFlow-2.2.0+34/tensorflow/fcc_build_script/.local/example/01_resnet/checkpoint_multi/resnet0/model.ckpt-0_temp_a191bdeae6ca4d59b2cb2b66ef0b1810/part-00000-of-00001.index
/vol0004/rccs-atd/a01004/TensorFlow/build/TensorFlow-2.2.0+34/tensorflow/fcc_build_script/.local/example/01_resnet/checkpoint_multi/resnet0/model.ckpt-2_temp_a191bdeae6ca4d59b2cb2b66ef0b1810/part-00000-of-00001.index
(省略)
14-1_train_llio_main.shでは、
cat ./llio_transfer.list | xargs -L 100 llio_transfer
として、計算の前にリスト内の2,000ほどのファイルを第1階層に転送しています。
2.8.4. SpackによるPython moduleの利用¶
実際にTensorFlowを用いて学習する際には、/vol0004/apps/oss/TensorFlow-2.2.0に用意されたPython moduleだけでは足りず、自分でPython moduleを組み込む必要があります。
一般には、以下の方法で、$HOME/.localに必要なPython moduleを構築して組み込
むことができます。
$ . env.src
$ wget https://(...module_name...)
$ cd (module_name)
$ python3 setup.py clean
$ python3 setup.py bdist_wheel
$ pip3 install --user dist/*.whl
なお、TensorFlowで使用するPythonは富士通Cコンパイラのclangモードにて構築しているため、 上記方法では、Python moduleも富士通コンパイラにて構築されます。
外部Python moduleを使用する際には、システムからSpackにて提供されているものを使用する
こともできます。Spackでは、あとからloadしたPythonやPython moduleが、動かすために必要
な環境変数LD_LIBRARY_PATHやPYTHONPATHが上書きしますので、使い
たいモジュールをなるべく最後に読み込むようにします。
$ pjsub submit_spack.sh
実際にSpackの設定や提供モジュールを読み込んでいるのは、../env.src.spack内
からです。
$ # Spack
$ export PYTHONPATH=${PREFIX}/lib/python3.8/site-packages-pycache # Python cache(*.pyc)を読み込むとbus errorが発生することがあるため、別のsite-packagesを優先的にimportするようにします
$ . /vol0004/apps/oss/spack/share/spack/setup-env.sh # Spackを利用するための環境設定
$ export LD_LIBRARY_PATH=${TCSDS_PATH}/lib64:${PREFIX}/lib64:${PREFIX}/lib:${LD_LIBRARY_PATH} # for 'lsb_release -a' error
$ spack load /bo2w4et #py-mpi4py@3.1.2%fj@4.7.0 arch=linux-rhel8-a64fx # mpi4pyをSpackで利用する
$ export LD_LIBRARY_PATH=/lib64:${LD_LIBRARY_PATH} # for 'lsb_release -a' error
$ spack load /7sz6cn4 #python@3.8.12fj@4.7.0 arch=linux-rhel8-a64fx
$ export LD_LIBRARY_PATH=/lib64:${LD_LIBRARY_PATH} # 現段階で問題が発生することがあるため最後に必ず環境変数を並べ替え
$ which python3 # どのPythonが動作しているか確認
$ python3 -c "from mpi4py import MPI" # 動作確認
TensorFlowでは、pthreadを有効にするなどPythonの構築方法が他のPythonと多少異なるため、
エラーを避けるためsite-packagesの調整や、spack loadごとに
LD_LIBRARY_PATHの調整が必要になります。
2.8.5. 性能プロファイルの取得¶
AI計算をしていると、性能が出ているのかの確認が必要になる場合があります。性能 プロファイル情報を取得する方法としては、TensorFlow標準のtensorbord、 富士通プロファイラ、Python標準のcProfileなどの利用が使用できます。しかし、制限事項 でも記載されている通り、TensorFlowはpthreadを用いたthread並列を行なっているため、富士通 プロファイラの一部機能は動作しません。ここでは、TensorFlow標準プロファイラ、 Python標準のcProfileの使用例を紹介します。
TensorBord:NNの関数レベルでコストを出力することができます。外部の環境でブラウザを使用して可視化できます。
富士通プロファイラ:バイナリの関数レベルで分析できます。インバランスやMPIのコストも取得できます。またfappやPAを使用することで、詳細のHWカウンタ情報を取得できます。
cProfile:Python処理レベルで分析できます。
TensorFlow標準のプロファイラを動かす場合は、
$ pjsub 18_train_4procs_prof.sh
です。models/official/r1/resnet/imagenet_main.pyの一部を置き換えること
でプロファルを取得できます。
$ diff models/official/r1/resnet/imagenet_main.py models/official/r1/resnet/imagenet_prof.py
404c404,405
< with logger.benchmark_context(flags.FLAGS):
---
> #with logger.benchmark_context(flags.FLAGS):
> with tf.profiler.experimental.Profile('tf_log'):
結果は、ジョブ内で指定したフォルダtf_log.4procs.20220104_052948に出力されます。
このフォルダをTensorBoardをインストールしてあるPCなどにコピーし、TensorBoardで読み込ませる
こととで、ブラウザで可視化できます。
$ tensorboard --logdir tf_log.4procs.20220104_052948/ # TensorBoardをインストールしているPCなどにて起動
$ /cygdrive/c/Program\ Files/Google/Chrome/Application/chrome.exe http://localhost:6006/ # cygwinからのChromeを起動し可視化する例
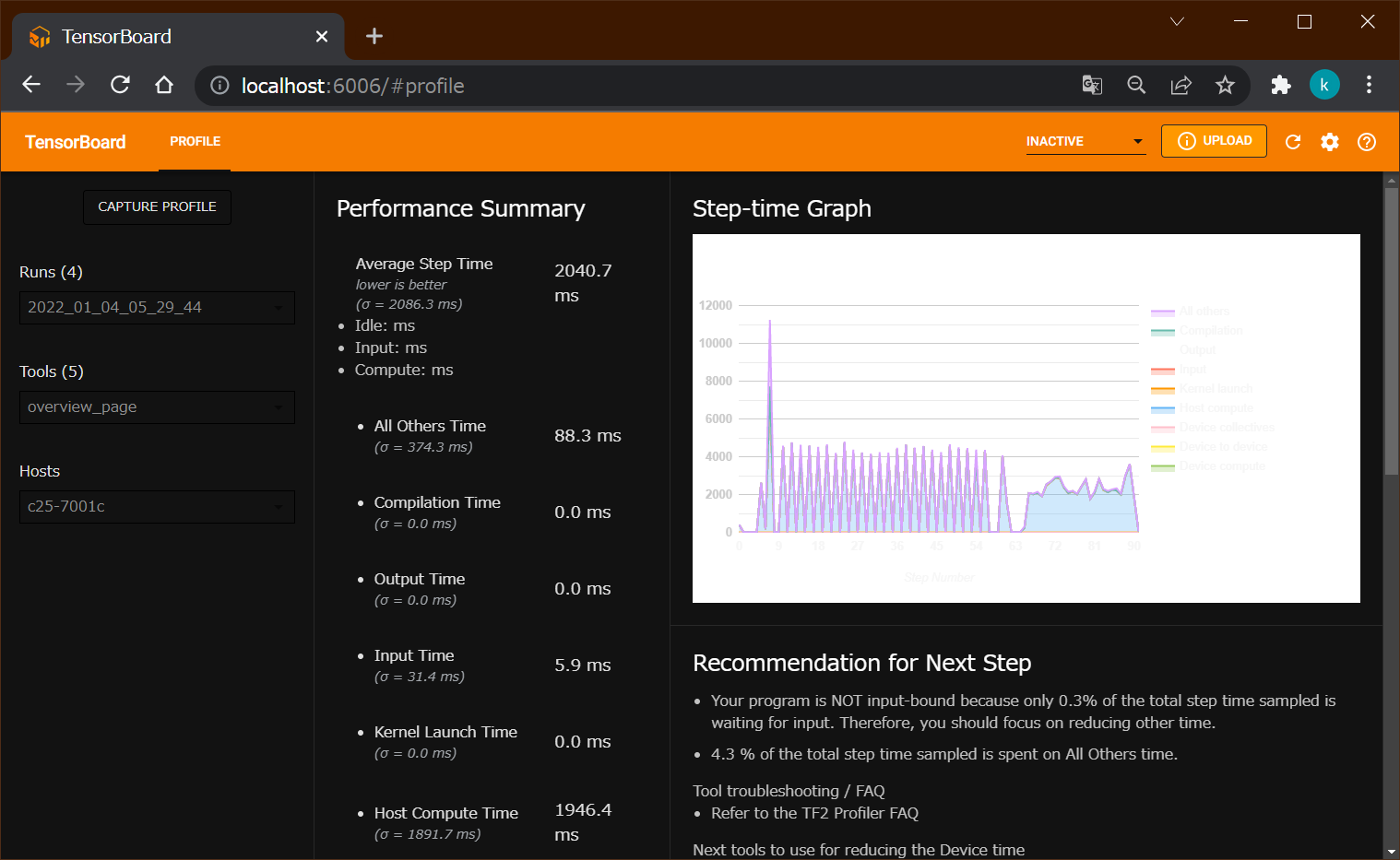
TensorBoardを用いた可視化例¶
cProfileを使用する場合は、
$ pjsub 19_train_cProf.sh # cProfileにてコスト分布を取得する
profile.txtにプロファイル情報が出力されます。
$ less profile.txt # 出力されたプロファイル情報を見る
Tue Jan 4 05:43:49 2022 profile.stats
119037552 function calls (110714773 primitive calls) in 502.802 seconds
Ordered by: internal time
ncalls tottime percall cumtime percall filename:lineno(function)
92 200.510 2.179 200.510 2.179 {built-in method tensorflow.python._pywrap_tf_session.TF_SessionRun_wrapper}
2400232/1537678 27.347 0.000 84.521 0.000 /vol0004/apps/oss/TensorFlow-2.2.0/lib/python3.8/site-packages/google/protobuf/internal/python_message.py:498(init)
1916659/595339 14.772 0.000 76.502 0.000 /vol0004/apps/oss/TensorFlow-2.2.0/lib/python3.8/site-packages/google/protobuf/internal/python_message.py:1053(ByteSize)
1474380/606629 12.885 0.000 62.910 0.000 /vol0004/apps/oss/TensorFlow-2.2.0/lib/python3.8/site-packages/google/protobuf/internal/python_message.py:1309(MergeFrom)
(省略)
cProfileを使用するためには、cProfileモジュールをimportして、 測定したい区間をcProfile.run()でくくり出すことでプロファイルが取得できます。
$ diff models/official/r1/resnet/imagenet_main.py models/official/r1/resnet/imagenet_cProf.py
411c411,413
< absl_app.run(main)
---
> #absl_app.run(main)
> import cProfile
> cProfile.run('absl_app.run(main)', filename='profile.stats')
また、gprof2dot、Graphvizのdotコマンドを使用することで、
コールグラフをツリー可視化することもできます。
$ gprof2dot -f pstats profile.stats -o profile.dot
$ dot profile.dot -T svg -o profile.svg
cProfileを用いた可視化例¶
2.9. 注意¶
高速化のために富士通研究所が開発中の ``oneDNN-2.7.0``以下のバージョンを使用しています。画像認識、自然言語解析など処理の高速化しております。 使用するネットワークによっては、不具合や高速に動作しない関数がある可能性もございますので、問題がある場合は、何らかの別の関数に置き換えるなどにより対応下さいますようお願い致します。
高速化、サポートバージョン、モジュールなどの要望は、使用するネットワークスクリプトをご呈示の上、利用者アカウントのサポートデスク(運技サポートデスク若しくはHPCIサポートデスク)へ御願い致します。対応に数ヶ月を要することもございますのでご了承下さいませ。
2.10. 将来の対応予定¶
済 Mask R-CNN版のTensorFlowの提供 (2021.4頃)
済 OpenNMTの制限事項の解除 (2021.4頃)
済 オプショナル機能TensoFlow_CC.so、OpenCV, Keras-2
済 Python modue: mpi4pyの提供 (2021.4頃)
済 オプショナルPython modue: netcdfの提供 (2021.4頃)
旧バージョンへの対応 (2021.4頃)
fipp/fapp/PAへの対応 (未定)
Spackによるユーザ環境でのbuild (2021後半頃)
Singurarityによるコンテナ提供 (2021後半頃)
富士通言語環境への追従 (随時)
TensorFlow, oneDNNバージョンアップへの追従 (随時)
サポートモジュールの拡大 (随時)
FX700での提供 (2021後半頃)
2.11. 履歴¶
2020/08/06(木) TensorFlow-2.1.0公開
ImagNetサポート、tcsds-1.2.26で構築
2021/02/13(土) TensorFlow-2.2.0公開
tcsds-1.2.29で構築
OpenNMT、Bertサポート、mpi4py、pandas追加
2021/02/21(日) tcsds-1.3.30aで構築
2021/05/20(木) Mask R-CNN対応、oneDNN-2.1.0L1を組み込み
TensorFlow-2.2.0をtcsds-1.3.31で構築
OpenNMTサンプル22でNaNとなる問題を修正
2021/10/15(金) ドキュメント公開(Ver.1.0)
2021/12/07(火) ドキュメントアップデート(Ver.1.1) LLIO使用を推奨
2021/12/23(水) tcsds-1.2.34で構築
01_resnet: spack sample、llio sample 未動作
04_Mask-R-CNN: OpenCVインストール不十分
2021/12/26(日) libTensorFlow_cc修正、04_Mask-R-CNN修正対応
vol0004以外ユーザの対応、ユーザ環境でのサンプル実行対応
01_resnet: spack sample、llio sample 未動作
2022/01/03(月) 01_resnet: spack sample、llio sample対応
2022/01/04(火) 01_resnet: tf.profiler、cProfile sample対応
2022/2/28(月) ドキュメントアップデート(Ver.1.2) 日本語チュートリアルを追加
2023/7/13(木) ドキュメントアップデート(Ver.1.3) 新バージョン(TensorFlow-2.11.0など)に関する記述記載