2. Storage Overview¶
2.1. Job submission flow¶
A user can execute a job on the compute node side by logging in to the login node and requesting to place a file in FEFS and execute a job.
While the job is running, the FEFS reads and writes files as needed.
After the job ends, the user can view the files output during job execution from the login node.

2.2. Overview of Fugaku Storage Configuration¶
Storage of the supercomputer Fugaku.
2.2.1. File system available in Fugaku¶
Fugaku supports two file systems:
FEFS (Fujitsu Exabyte Filesystem) : Second-layer storage
It is a file system developed by “K” and consists of disk drives. Suitable for large volumes of data or data to be stored for a long time.
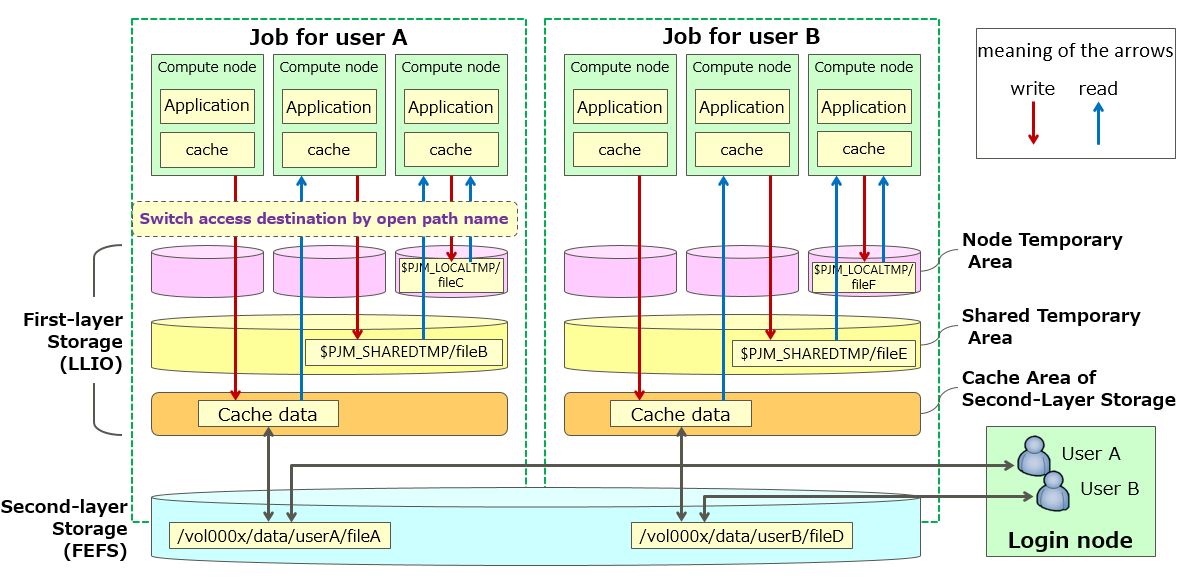
LLIO (Lightweight Layered IO-Accelerator) : First-layer storage
It is a dedicated file system for job execution, aiming for ease of use of hierarchical storage and faster I/O of application files. It is composed of SSDs and offers three types of areas for different purposes.
LLIO Area¶ Area
Namespace
Use
Cache Area of Second-Layer Storage
Second-Layer Storage
[Save file]
There are two types of storage: First-layer storage (LLIO) and Second-layer storage (FEFS). Cache function for FEFS that can be used during job execution.
When an application issues a READ request for a file, LLIO automatically reads the file data from the second-layer storage (FEFS) to the first-layer storage (LLIO) for caching.
When an application issues a WRITE request, it buffers the first-layer storage and LLIO writes to the second-layer storage (FEFS) asynchronously with application execution.
Directories and files created during job execution are not deleted after the job ends.
Shared temporary area
Intra-job share
[Temporary file]
A temporary area that can be used to share files within a job while the job is running. It is independent of second-layer storage (FEFS).
It is suitable for storing temporary files that share read and write data among multiple compute nodes on which an application is running. A temporary file system is created when the application is started using first-layer storage (LLIO).
After the job ends, the file system is automatically released and any directories and files created during the job are deleted.
Node temporary area
Intra-job share
[Temporary file]
A temporary area closed within one node that can be used during job execution. It is independent of Second-layer Storage (FEFS).
Creates a temporary file system when the application starts using first-layer storage (LLIO).
After the job ends, the file system is automatically released and any directories and files created during the job are deleted.
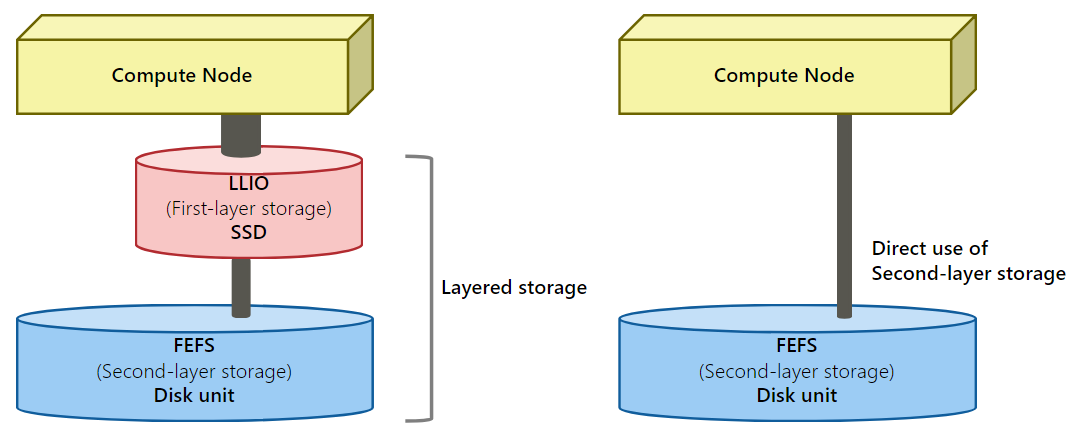
2.2.2. About Layered Storage¶
Layered storage is a file system that combines first-layer storage (LLIO) for high-speed access and second-layer storage (FEFS) for long-term storage of large amounts of data. By processing IO from multiple compute nodes, you can expect fast access to files.
Reference : Performance of File System
Access method
Access from jobs (compute nodes)
Access the second-layer storage through the first-layer storage
Access the second-layer storage directly.
Access from the login node.
Access the second-layer storage directly.
Notes
Please refer to Users Guide - Use and job execution.
2.2.3. Layered Storage Decision Flow¶
The availability of FEFS/LLIO can be checked using the following flow.
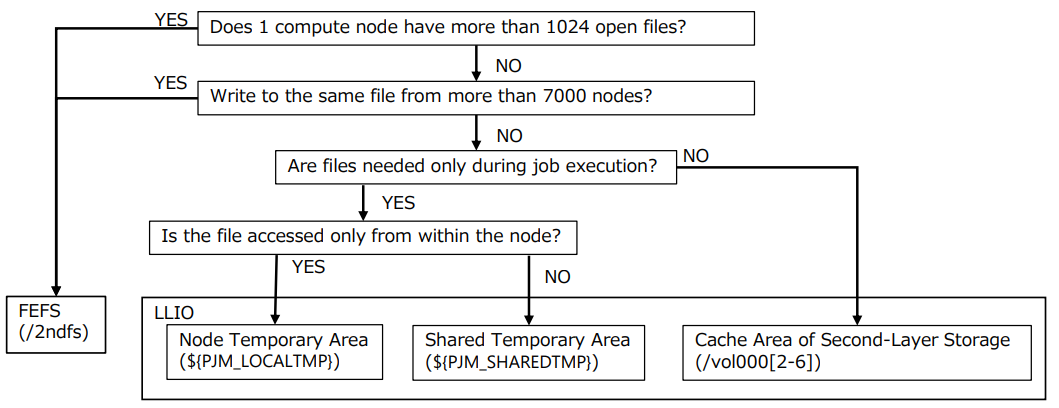
The LLIO area might not be available depending on the capacity. Use the FEFS area (/2ndfs). For details, refer to First-Layer Storage Capacity Settings .
2.3. First-layer Storage¶
First-layer storage provides three types of space as shown.
2.3.1. About Node Temporary Area¶
A temporary area enclosed within a compute node that provides fast access to temporary files.
Advantages |
Points to consider |
|---|---|
|
|
How to use
Specify the job parameter “localtmp-size” in the job script.
The access path is set to the environment variable “PJM_LOCALTMP”.
Usage examples(1) : Improving Performance of File Access Closed in Nodes.
After specifying a temporary area in the node in the TMPDIR environment variable, you can expect fast file access for files read or written to this DIR. The following is an example script for prog1 that creates an intermediate file in the TMPDIR environment variable.
Job scripts that do not use node temporary Area.
#!/bin/bash -x #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4" #PJM -s export TMPDIR=${TMPDIR}/temp mkdir -p ${TMPDIR} mpiexec ./prog1 rm –rf ${TMPDIR}/* #Delete intermediate filesJob scripts using node temporary area.
#!/bin/bash -x #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4" #PJM --llio localtmp-size=30Gi # Specifies the amount of Node temporary area #PJM --llio perf # Output of LLIO performance information #PJM -s export TMPDIR=${PJM_LOCALTMP} mpiexec ./prog1 #File system disappears after job completion, so no need to delete
Usage examples(2) : Pre-deploy files for faster file access.
If there are executables or multiple input files, archive them. Transfer the archive file to a node temporary area and extract it before running the job. This allows you to expect fast access to these files during job execution.
The following example expands an archive file into a node temporary area.
#!/bin/bash -x #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4" #PJM --llio localtmp-size=30Gi # Specifies the amount of Node temporary area #PJM --llio perf # Output of LLIO performance information #PJM -s # Copy archive.tar to second-layer storage cache llio_transfer ./archive.tar # Extract archive.tar from one process in the node mpiexec sh -c 'if [ ${PLE_RANK_ON_NODE} -eq 0 ]; then ¥ tar xf ./archive.tar -C $PJM_LOCALTMP; ¥ fi # Delete archive.tar from second-layer storage cache llio_transfer --purge ./archive.tar # Run bin/prog1 in the archive.tar mpiexec $PJM_LOCALTMP/bin/prog1
2.3.2. About Shared Temporary Area¶
A closed temporary area within a job that provides fast access to temporary files.
Advantages |
Points to consider |
|---|---|
|
|
How to use
Specify the job parameter “sharedtmp-size” in the job script.
The access path is set to the environment variable “PJM_SHAREDTMP”.
Usage examples: Speed up access to files bound in a job, such as the progress of the job
By outputting the progress of the calculation to a shared temporary area, you can expect fast access to the file from the program. The following example script reads the results of job prog1 and outputs the final calculation results to job prog2.
Job scripts that do not use shared temporary Area.
#!/bin/bash #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4" #PJM -s ### 1. Program prog1 prints out.data in the FEFS area. mpiexec ./prog1 -o ./out.data ### 2. Program prog2 reads out.data and ### outputs the final result.data. mpiexec ./prog2 –i ./out.data -o ./result.data
Job scripts using shared temporary area.
#!/bin/bash #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4" #PJM --llio sharedtmp-size=10Gi # Specifies the amount of Node temporary area #PJM -s ### 1. Program prog1 outputs out.data to shared temporary area. mpiexec ./prog1 -o ${PJM_SHAREDTMP}/out.data ### 2. Program prog2 reads out.data and ### outputs the final result.data. mpiexec ./prog2 –i ${PJM_SHAREDTMP}/out.data -o ${PJM_SHAREDTMP}/result.data #### 3. Save result.data to the job execution directory before job termination. cp –p ${PJM_SHAREDTMP}/result.data ${PJM_JOBDIR}/result.data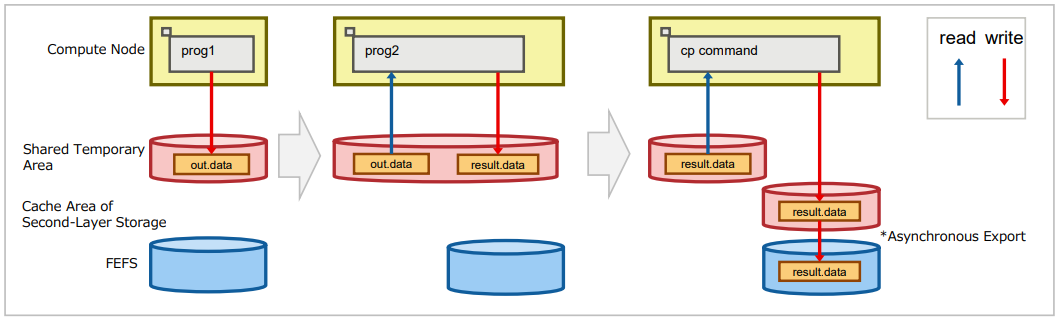
2.3.3. About Cache Area of Second-Layer Storage¶
You can expect fast access to files by caching data accessed in second-layer storage.
Advantages |
Points to consider |
|---|---|
|
|
How to use
The access path is the same path as the second-layer storage.
Usage examples: Faster file access during job execution.
If you read from the same file multiple times, the cached data is used and you can expect fast access to the file. The following is an example script for prog1.
Job scripts without cache area of second-layer storage.
#!/bin/bash #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4“ #PJM --llio sio-read-cache=off # Do not use cashe area of second-layer storage #PJM -s ### 1. Program prog1 prints out.data in the FEFS area mpiexec ./prog1 ./in.data -o ./out.data
Job scripts that leverage cache area of second-layer storage.
#!/bin/bash #PJM -L "rscunit=rscunit_ft01" #PJM -L "node=48" #PJM -L "rscgrp=small" #PJM -L "elapse=1:00:00" #PJM -g groupname #PJM --mpi "max-proc-per-node=4“ #PJM --llio localtmp-size=0Gi # Specifies the amount of node temporary area. #PJM --llio sharedtmp-size=0Gi # Specifies the amount of share temporary area. ### Capacity of cache area of second-layer storage is: ### 87GiB - (node temporary area + shared temporary area) #PJM --llio sio-read-cache=on # Specify use of cache area of second-layer storage #PJM -s ### 1. Program prog1 outputs out.data to cache area of second-layer storage. mpiexec ./prog1 ./in.data -o ./out.data
2.4. About Second-Layer Storage¶
Second-layer storage is a parallel distributed file system that can store large files.
Advantages |
Points to consider |
|---|---|
You can use FEFS for application work areas and areas under /home. |
Each user has a limited capacity. If you need more capacity, you need to apply. |
How to use
Second-layer storage is the area that you can log into a login node and access as home and data areas.From the compute node, you can access the file using the same file path as above, but through first-tier storage.To access second-layer storage from a direct compute node, use the dedicated space/2ndfs. Please check Users Guide - Use and job executionfor details on how to use /2ndfs.